Tech
Tero Laitinen
Sep 9, 2024
Streaming Personalized Content on First Load at Wolt.com

Generic web page content can be included in cached HTML pages and quickly served to users. However, personalized content for authenticated users often needs to be generated on demand, which leads to more network round trips, higher latency, and a suboptimal user experience.
Wolt.com stores the session information for a logged-in user, required to access personalized content, in a pair of tokens: a short-lived JWT-based access token and a long-lived refresh token. When a logged-in user returns to the website, the access token may require renewal using the refresh token before the web application can fetch user-specific data. This renewal process necessitates an additional round trip.
Websites often redirect users landing on the root path to other pages that may include country and locale information in the URL. This approach allows these pages to be indexed in search engines and cached more effectively in a CDN. In our case, the server application redirected unauthenticated requests to country-specific landing pages. Requests from logged-in users were redirected to the discovery page, causing yet another round trip. On this page, users can explore available restaurants, stores, offers, and products.
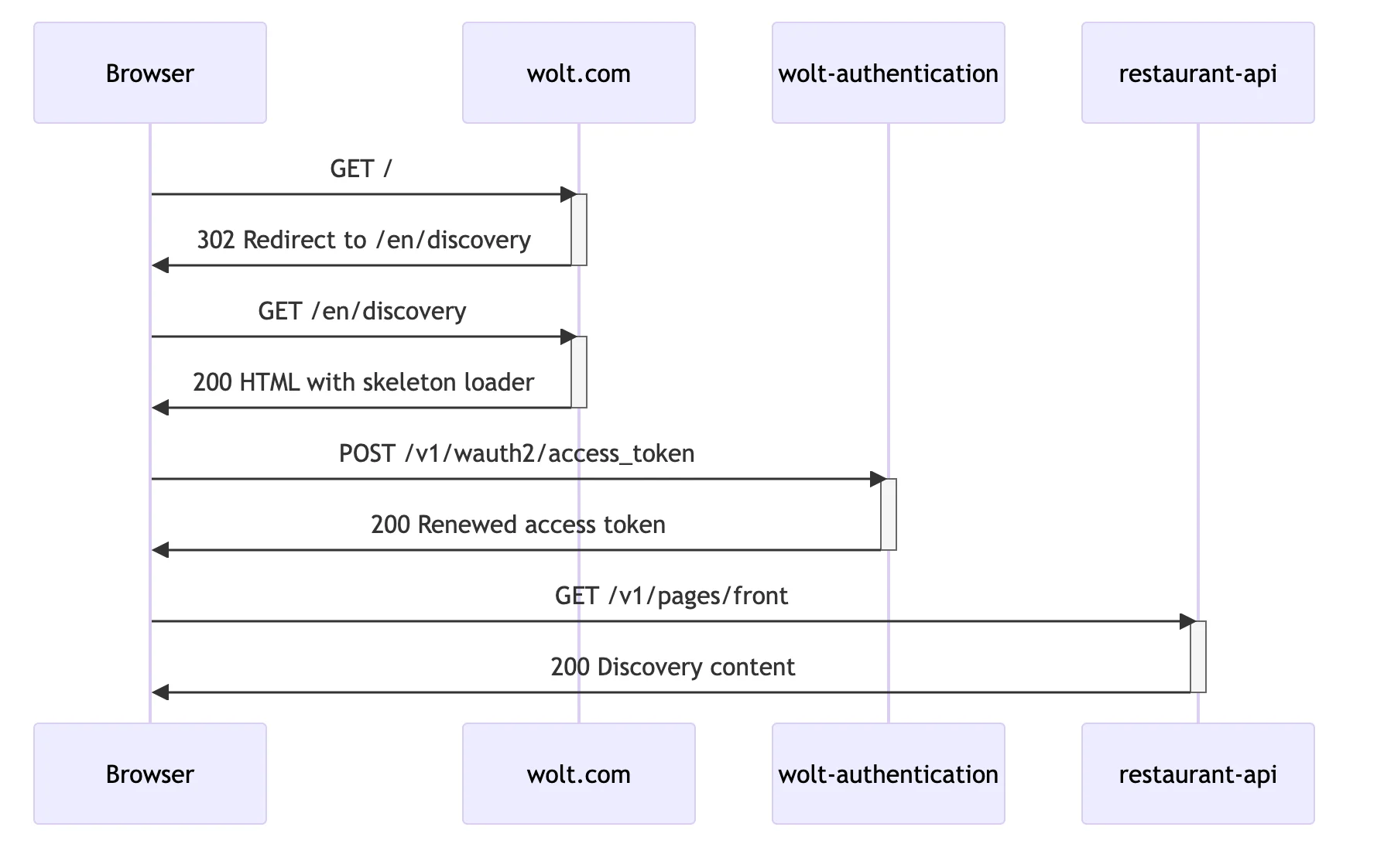
We set out to optimize the discovery page content delivery for logged-in users and managed to eliminate three round-trips by:
Moving the server-side redirect of authenticated users from the root path to the discovery page to the browser.
Renewing expired access tokens on the server during the first load.
Fetching user-specific discovery content on the server and streaming the data in the initial connection.
For the data streaming part, leveraging React’s streaming rendering would have been ideal, but some of our package dependencies, like styled-components, presented hurdles that were laborious to overcome. A migration path for unlocking the library-provided streaming solution is clear, and we will undoubtedly adopt the industry best practices for web page data streaming in the near future. While work for a long-term solution continues, we implemented a tailored yet minimal change to our current server-side rendering app, enabling it to stream discovery content in the same connection as the page HTML.
The request waterfall optimizations led to a significantly lower latency for our users, improving the user experience the most in places farthest from the servers. Results indicate up to a 50% reduction in median loading time in some markets.

Moving Discovery Page Redirect From Server to Browser
Wolt.com has redirected unauthenticated requests at the root path (/) to country-specific landing pages (/:locale/:country) and authenticated requests to the discovery page (/:locale/discovery). Including locale and country information in URLs allows search engines to index localized pages, and page caching can be implemented more effectively.
In the initial version of the website, the discovery page for logged-in users could have been at the root, but we included locale and page information in the URL for consistency. In the early days of Wolt, we quickly implemented a server-side redirect from the root to the discovery page to simplify server-side rendering and page HTML hydration and then moved on to build other functionality. Since then, we have opened new markets where users experience higher latencies to our servers, so revisiting the design decision concerning the redirect was due.
Moving the redirect functionality to CloudFront functions, which run on CloudFront edge servers close to users, was an option. However, the 10 kB function size limit, relatively poor developer experience, and the risk of bringing down the site with a bad function quelled our enthusiasm for adding more logic to CloudFront functions.
Instead of adding complexity to the infra level, we reconsidered the design decision to redirect all requests on the server to other pages. Since the redirect involved only authenticated users, we could move it to the browser application without endangering search engine results. However, moving only the redirect functionality would have impacted server-side rendering. Without additional changes, the browser would have displayed a blank page until the JavaScript bundle was ready to run, redirecting the user to the discovery page, and rendering the page.
Showing a blank page while waiting for the browser application to run would have worsened the user experience for the loading state, so we modified the Node.js application to render the skeleton loader for the discovery on the server for authenticated requests at the root (/). Rendering a loader on the server at the root led to another complication with React’s hydration. When the browser application hydrates a DOM element on the page, the client-side render must match the server-side render. Rendering the page with “/:locale/discovery” passed as the location to StaticRouter on the server and hydrating it at the root in the browser results in a hydration error.
To solve the mismatch between how the server and the browser render the page, we added an attribute to the body element, data-ssr-pathname, which records the location passed to StaticRouter on the server. On the client side, before hydrating the page, the application checks if the attribute is present and navigates to the pathname indicated by the attribute.
After removing the round trip related to the server-side redirection, the next step was to optimize the delivery of the discovery page’s content, which is produced on demand for each user.
Renewing Access Token on the Server on the First Load
Fetching personalized content requires a valid access token. These tokens typically have a short expiration time, so that permission updates can be propagated quickly and sessions can be revoked from the server. The application periodically renews its access token using a long-lived refresh token. When a logged-in user returns to wolt.com, the access token is often expired. Hence, the application must renew it before loading discovery page content, postponing the moment the user can interact with the website by one network round trip.
To eliminate this round trip, we added a new Express middleware that renews access tokens. In short,
The middleware validates and decodes the access token if it is present in the request’s cookie header.
Next, it makes a request to the authentication service with the refresh token if the access token has expired or is about to expire.
The module, which hosts the middleware, exports a function that returns the new access and refresh tokens to the browser using the
Set-Cookieresponse header.
The middleware does not block request processing, so it avoids introducing a request waterfall on the server. Instead, it stores a promise in the Express request object using a Symbol-keyed property. When resolved, the promise holds the response of the access token renewal request. Crucially, with this design, we only need to await the promise when needed, and it is likely to have resolved while other data requests are in flight.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18const reqSymbol = Symbol('accessTokenRenewalRequest'); type RequestWithAccessTokenRenewalRequest<TParams> = Request<TParams> & { [reqSymbol]?: Promise<PostWauth2AccessTokenV1Response | undefined>; }; const getAccessTokenRenewalRequest = <TParams>( req: RequestWithAccessTokenRenewalRequest<TParams>, ) => req[reqSymbol]; const setAccessTokenRenewalRequest = <TParams>( req: RequestWithAccessTokenRenewalRequest<TParams>, accessTokenRenewalRequest: Promise<PostWauth2AccessTokenV1Response | undefined>, ) => { req[reqSymbol] = accessTokenRenewalRequest; };
Attaching custom properties to an Express request object is a convenient way to ensure that Node.js garbage-collects any additional request-specific data after serving the corresponding request. Using a Symbol as the key for a custom property in Express request objects is an implementation detail that has two appealing characteristics:
It guarantees that properties set in one middleware do not collide with properties set in another.
Other TypeScript modules cannot reference an unexported Symbol key, thus encapsulating its use within a single TypeScript module.
As an alternative to Symbol-keyed properties, the recently added AsyncLocalStorage provides similar guarantees with less boilerplate. However, it may have a higher performance overhead and implicitly relies on running a middleware before the code that accesses the computed property. Deriving properties from the Express request object and caching them in the object itself is not inherently sensitive to the order of middleware and can be more efficient. Only the derived properties needed for handling a particular request are computed, as opposed to providing them always in a middleware-based approach.
The middleware exposes a convenient function that returns the current access token included in the request if it has not expired; otherwise, it returns the renewed access token.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15/** Returns a new access token if the current one is expired, otherwise returns the current one. * * Note: this function can be called after `accessTokenMiddleware` has run */ export const getValidAccessToken = async <TParams>( req: RequestWithAccessTokenRenewalRequest<TParams>, ) => { const accessTokenRenewalRequest = getAccessTokenRenewalRequest(req); if (!accessTokenRenewalRequest) { // `accessTokenRenewalMiddleware` below checks if the token is expired and starts a renewal request. // If the request is not associated with a renewal request, it implies that the token in the request is valid and we can return it. return getAccessTokenFromRequest(req); } const accessToken = await accessTokenRenewalRequest; return accessToken?.access_token; };
When the other middleware functions have finished processing an incoming request and it is time to respond, the request handler in the page-rendering middleware can call the setAccessTokenAndRefreshTokenCookie function, which returns the new tokens to the browser using Set-Cookie response headers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27export const setAccessTokenAndRefreshTokenCookie = async <TParams>( req: RequestWithAccessTokenRenewalRequest<TParams>, res: Response, ) => { try { const now = Date.now(); const accessTokenRenewalResponse = await getAccessTokenRenewalRequest(req); if (!accessTokenRenewalResponse) { return; } const { access_token, expires_in, refresh_token } = accessTokenRenewalResponse; const accessTokenCookie = JSON.stringify({ accessToken: access_token, expirationTime: Math.floor(now / 1000) * 1000 + expires_in * 1000, }); const refreshTokenCookie = JSON.stringify(refresh_token); const cookieOptions = { expires: new Date(now + config.AUTH.COOKIE_TTL_DAYS * 86400 * 1000), secure: true, }; res.cookie(config.AUTH.ACCESS_TOKEN_NAME, accessTokenCookie, cookieOptions); res.cookie(config.AUTH.REFRESH_TOKEN_NAME, refreshTokenCookie, cookieOptions); } catch (error) { // In case something went wrong, we fall back on the client to refresh the token. log.info(`Error in setAccessTokenAndRefreshTokenCookie: ${String(error)}`); } };
In case the other middleware functions finish before the access-token-renewing request completes, the server waits for it to complete.
As a result, the web application is ready to make authenticated requests immediately after hydrating the page. Additionally, the server can make requests to endpoints requiring a valid access token, such as the discovery content endpoint.
Intermediate Bespoke Streaming Solution
Producing personalized content on demand requires aggregating data from multiple databases and services. The ongoing architectural and technical enhancements on the discovery backend yield continuously improving performance, but the endpoint serving discovery data is likely to take hundreds of milliseconds at least. Displaying a skeleton loader in the browser as quickly as possible is thus essential for the user experience. Since rendering the full discovery page on the server is challenging, streaming the discovery endpoint response after sending the skeleton loader in the same connection is the second-best alternative, minimizing the waiting time until the discovery page is browsable.
The long-term work towards leveraging React’s streaming rendering capabilities continues. At the time of writing, the documentation about Suspense mentions that “Suspense-enabled data fetching without the use of an opinionated framework is not yet supported.”. As a rule, we refrain from adding complexity with in-house solutions to problems for which the industry offers well-supported libraries. Ideally, we would have waited for the React API to stabilize. Yet in this case, we could not ignore the great potential to improve the discovery page user experience, emboldening us enough to consider a tailored solution that we could develop quicker. We carefully weighed whether the added complexity of a custom streaming approach was justifiable. The goal was to make minimal changes, as some of them would be discarded when we adopt Suspense-backed rendering.
The web application stores the user’s selected delivery active address in localStorage. It is available only in the browser, so the first change was to reflect a part of the state (coordinates) in a new cookie that the browser would send to the server. Storing information on the user’s device requires consent; allowing functional cookies is a prerequisite for using the feature.
With the user location and a valid access token available, the server can fetch personalized discovery content. The custom streaming implementation encodes the TanStack query’s query key and the JSON data from the discovery endpoint as a URI-encoded blob inside a “script” tag. The server first sends the loader skeleton rendered using renderToStaticMarkup. When the discovery data is available, the server sends it wrapped in the “script” tag and closes the remaining HTML tags by sending “</body></html>”.
The server application caches HTML pages in Redis. Previously, it could store full pages including the closing tags “</body></html>” in Redis entries. The revised implementation strips the suffix “</body></html>” from the full skeleton loader page HTML before caching it in Redis so that it can stream the data-containing “script” tag later.
Streaming data in script tags is currently enabled on three routes: the root path, the dynamic-location discovery page, and the city discovery page. The route configuration may specify different strategies to extract coordinates from the request.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17ssrSetup.addRoute({ method: 'get', path: '/', cacheTtl: 600, getDataScripts: createGetDiscoveryDataScripts( getActiveLocationFromRequest, // coordinates from cookie getGeoIpLocationFromRequest, // coordinates from IP-based rough ~50km geolocation ), // sets location for StaticRouter and data-ssr-pathname attribute getSsrPathname: (req) => { if (isAuthenticatedRequest(req)) { return renderRoutePath('/:locale/discovery', { locale: getReqLocale(req), }); } }, });
The route configuration also specifies an optional function for returning data to be streamed in script tags. The middleware responsible for rendering pages uses this function, which returns an array of promises. Each of these promises resolves to an object holding the ID attribute for a script tag and its content. The server uses encodeURIComponent to escape HTML-breaking characters. The encoding adds some overhead but hopefully compresses well. The page rendering middleware maps the data-script returning promises specified in the configuration into promises that return rendered “script” tags as strings.
1 2 3 4 5 6 7 8 9 10 11const dataScriptChunks = (routeConfig.getDataScripts?.(req) ?? []).map( async (dataScriptPromise) => { try { const dataScript = await dataScriptPromise; return dataScript ? renderDataScript(dataScript) : ''; } catch (error) { log.error(`Failed to render data script for ${req.url}: ${String(error)}`); return ''; } }, );
The middleware does not await the array of promises, which returns an array of data script chunks. Instead, it passes them to the function, which sends the response using chunked transfer encoding, waiting for each chunk-returning promise to resolve sequentially.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16await setAccessTokenAndRefreshTokenCookie(req, res); const chunks = [ Promise.resolve(pageWithoutClosingBodyAndHtmlTags), ...dataScriptChunks, Promise.resolve('</body></html>'), ]; return sendChunkedResponse(req, res, populateResult?.notFound ? 404 : 200, chunks, { contentLength: dataScriptChunks.length === 0 ? pageWithoutClosingBodyAndHtmlTags.length + closingBodyAndHtmlTags.length : undefined, contentType: 'text/html', compress: dataScriptChunks.length > 0, cspHashes, maxAge, }
When sending a single Buffer or string as a response, Express’s Response.send method automatically sets the Content-Length response header, required for leveraging CloudFront’s compression capabilities. Node.js defaults to Transfer-Encoding: chunked if the Content-Length is not explicitly set when sending a chunk, so the code calculates the length if possible. When the Node.js application streams script tags, it cannot set the Content-Length response header. Compressing the response at the origin remains the only viable option in this case. Node.js includes Gzip and Brotli compression functionality. By default, createBrotliStream uses the highest quality, which is computationally too intensive for on-demand compression. We found setting the Brotli compression quality setting to 6 a good compromise for balancing compression ratio and latency. The Zstandard compression algorithm may be more suitable than Brotli for compressing dynamic content, but Safari does not currently support it.
After the browser receives the unclosed HTML for the skeleton loader, it can load and run the JavaScript application. It uses document.readyState, the DOMContentLoaded event, and useSyncExternalStore to detect when the page is fully loaded.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15const subscribeToDomContentLoaded = (onChange: () => void) => { if (!isBrowser()) { return () => {}; } document.addEventListener('DOMContentLoaded', onChange); return () => document.removeEventListener('DOMContentLoaded', onChange); }; const isWindowInteractive = () => { return isBrowser() && ['complete', 'interactive'].includes(document.readyState); }; const useIsWindowInteractive = () => useSyncExternalStore(subscribeToDomContentLoaded, isWindowInteractive, () => false);
After the loading finishes, the application can try to extract discovery content from the script tag. If decoding succeeds, it stores the data in the TanStack Query’s cache. The corresponding useQuery is disabled until the script tag parsing finishes, ensuring that the application does not make a request to the discovery endpoint.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27export const useHydrateDiscoveryDataScript = () => { const isLoading = !useIsWindowInteractive(); const [isHydrating, setIsHydrating] = useState(true); const queryClient = useQueryClient(); const { user } = useAuthState(); useEffect(() => { if (isLoading || !isHydrating) { return; } const content = decodeDiscoveryDataScript(); setIsHydrating(false); if (!content) { return; } setDiscoveryQueryData( queryClient, { lat: content.lat, lon: content.lon, locale: content.locale, userId: user?.id, }, content.data, ); }, [isLoading, isHydrating, user, queryClient]); return isHydrating; };
We enabled the three improvements (client-side redirection, server-side access-token renewal, and streaming discovery content) using a single flag to analyze the aggregate effect on loading time.
Analyzing the Impact of Fewer Request Waterfalls
For the experimental part, we have two complementary measurements to assess the impact of the changes:
Benchmarking how quickly the discovery page loads in a single browser.
Analyzing the average loading time as reported by DataDog Real User Monitoring.
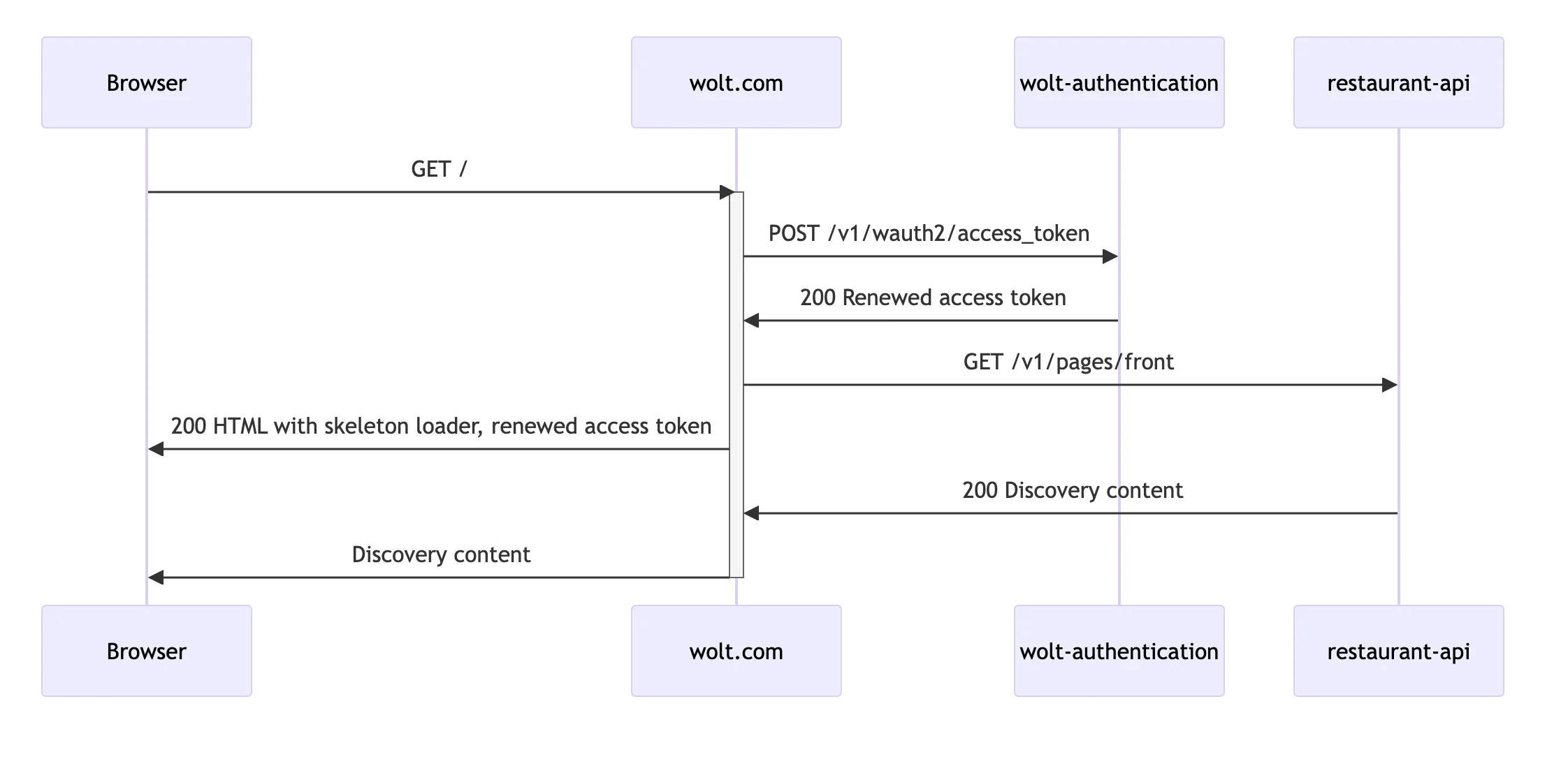
The single-browser experiment measures the waiting time from the first request until the browser renders the discovery content. Caching is disabled, and the root page (https://wolt.com) is loaded with “Fast 4G” network throttling using Chrome. We modified the access token cookie’s expiration time value before running the experiment to force an access token refresh. The baseline version makes four network requests in total to fetch data from the discovery content endpoint.
In the optimized version, the browser makes one request to the server. During the processing of the request from the browser, the Node.js application makes a request to renew the access token and fetches the discovery content.
A single measurement as described below is not statistically significant, but it serves to illustrate what kind of effect it can have in practice. The loading time is primarily defined by network and endpoint latencies, assuming the browser is running on reasonably capable hardware. In the screen capture video below, the optimizations are turned off, and the loading time is 4.86 seconds.
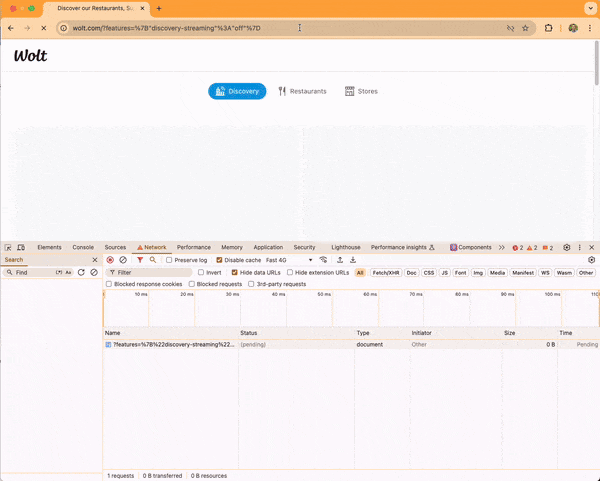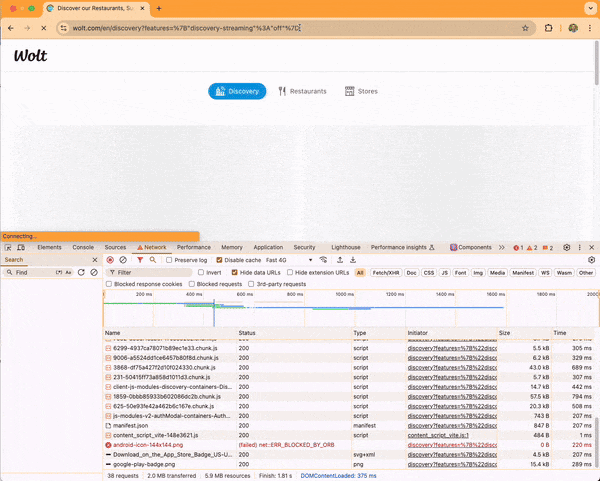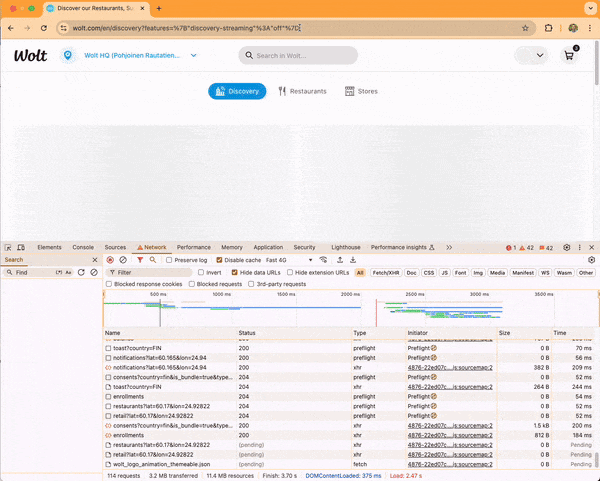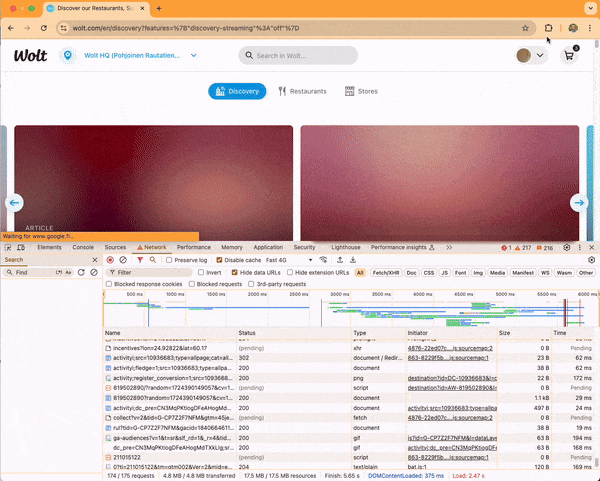
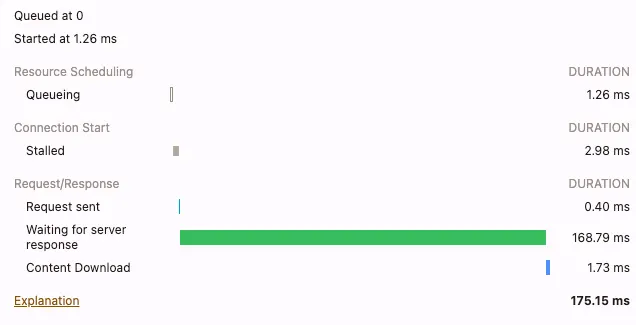
The initial request to https://wolt.com takes 175 milliseconds. The Node.js app quickly serves a redirect to https://wolt.com/en/discovery.
The second request to https://wolt.com/en/discovery takes 374 milliseconds.

The browser must fetch the JavaScript bundle because caching is disabled. After loading and running the JavaScript application, it queues the request to renew the access token at 2.83 seconds, and the request takes 276 milliseconds once it clears the queue.

Finally, with the renewed access token, the JavaScript application fetches the discovery content at 3.13 seconds, taking 1.49 seconds in total waiting for the server and transferring the content.
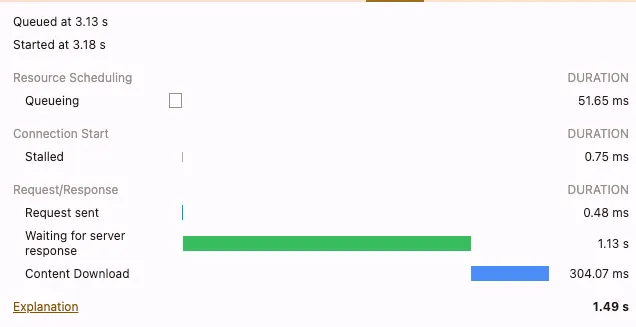
The next screen capture video shows an optimized run with a loading time of 3.10 seconds.
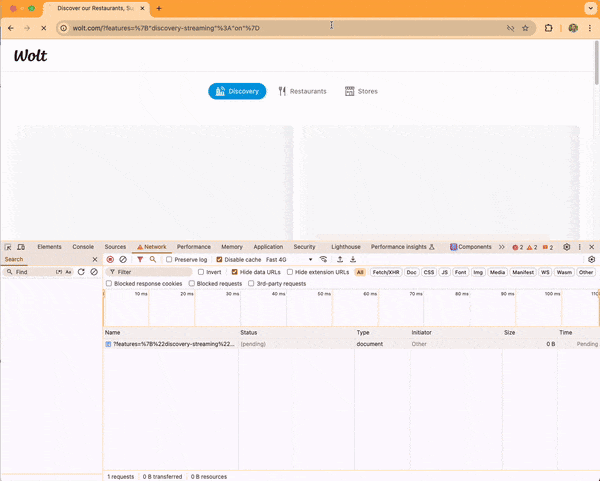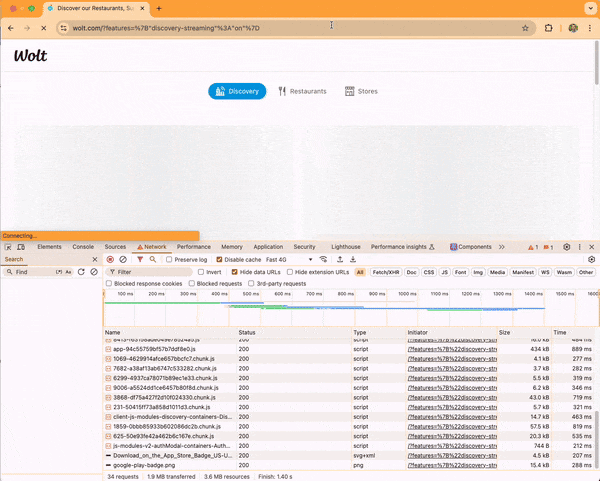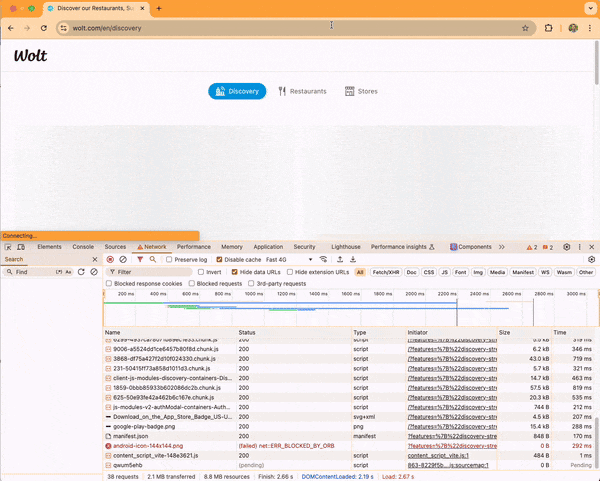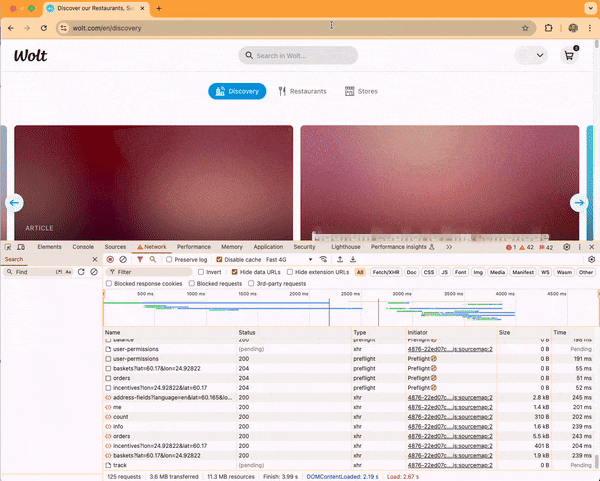
Here, the browser makes only one request to load the skeleton loader HTML, renew the access token, and fetch the discovery content, taking 2.19 seconds to finish. After that, it fetches the JavaScript application and renders the discovery content.

In this artificial experiment, the loading time decreased by 36%. We can arbitrarily amplify the difference by throttling the network connection more aggressively.
But do our users actually benefit from these improvements? We have instrumented the JavaScript application to record the time when the discovery content is available in the TanStack query’s cache and report it to DataDog Real User Monitoring. The chart below shows how the optimizations affect the median loading time in Wolt countries.
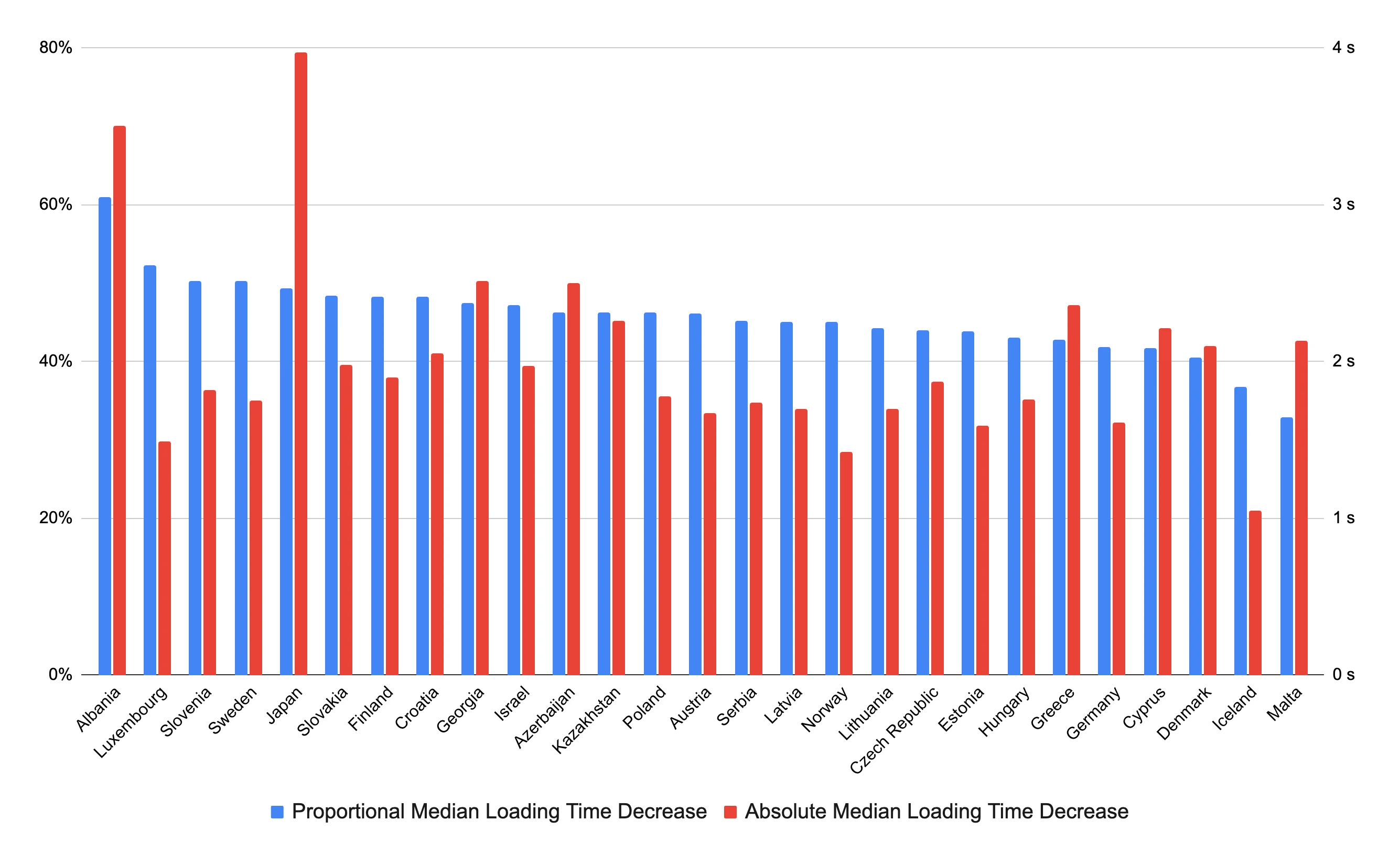
The biggest absolute reduction in loading time is in Japan, which is expected because it’s the Wolt country with the highest network latency to Ireland, where our servers are located. However, the proportional decrease in loading time does not strongly correlate with the average backbone network latency between a Wolt country and Ireland. Variations in mobile network latency and throughput characteristics may partially explain these results. Additionally, backend endpoint latencies may vary by country.
Conclusions
An obsession with user experience guided us to optimize the loading time of the most important page for authenticated users, the discovery page. Many customers start browsing by typing “wolt.com” in the address bar and can benefit from seeing the content one round-trip request faster, thanks to moving the discovery page redirection from the server to the browser. Regardless of the landing page, all logged-in users save another round-trip request thanks to the server-side access token renewal. While work continues on adopting library-provided data-streaming capabilities in conjunction with server-side rendered pages, our custom discovery content streaming solution significantly shortens the median loading times in all Wolt countries.
As developers, we sometimes assume that everyone is not only on a fast connection, but also on a stable connection with low latency. However, when looking at the improvements across the board, it seems that round trip time and latency optimisations are important even for locations close to the origin servers.
The technical landscape for further optimizations has intriguing possibilities. Ideally, the data required to produce discovery content would reside closer to the user, but a geographically distributed fleet of Kubernetes clusters poses a formidable engineering challenge. Smaller opportunities like JavaScript bundle size reduction and JavaScript application performance optimization could yield incremental yet meaningful gains. Would it be possible to keep an up-to-date prerendered discovery page cached for all authenticated users, assuming they will request the same location as before? We will explore the most promising leads and place our well-calibrated engineering bets accordingly.
Are you tempted by the complexities of building geographically distributed web applications? Do you feel excited about performance-related numbers going up or down? If the answer is yes, we assure you that Wolt is just the place for people like you and invite you to explore opportunities on our careers page. 💙