Engineering
Mathis Møller
May 19, 2023
Improving wolt.com Latency by Demystifying Node.js DNS Resolution

At Wolt, we strive to build excellence and understand the importance of providing our users with a lightning-fast experience. Users appreciate quick responses, and any delay, no matter how small, can result in lost conversions. In fact, even one additional second in load time can impact conversion by up to 20% in retail. That's why we're excited to share our journey of how we improved the latency of our web app wolt.com. By demystifying the Node.js DNS resolution process, we were able to identify a bottleneck and resolve it. Surprisingly, a single line of code became the major improvement for our latency.
In this blog post, we will take you through the steps we took to improve our application's latency. From identifying the issue to implementing a solution, we'll share our insights and learnings with you. So, join us on this journey and learn how we optimized our web application's performance with a simple but powerful change.
Investigating Spiky Latency
While monitoring our dashboard for wolt.com in Datadog, we observed fluctuating spiky latency patterns. We explored several avenues without success until we started analyzing high latency traces to determine if there were any similarities. Strangely, since the traces had high latencies primarily max latencies or the highest percentiles, no clear patterns emerged.
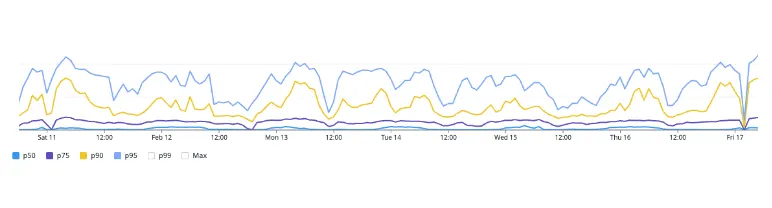
Later, we came across the issue of spiky TCP.connect times that were similar to request latencies. However, we could not identify any other network-related problems or bottlenecks in the pods in our Kubernetes cluster. This led us to investigate DNS resolution because if it were a general network issue, then all backend service calls would be affected. Upon analyzing DNS resolution times from all traces, we made a breakthrough discovery. As expected, generally TCP connect latency was low, however, the p99 and max correlated with the latency of DNS lookups.
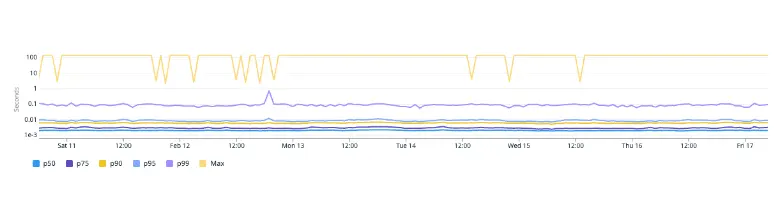
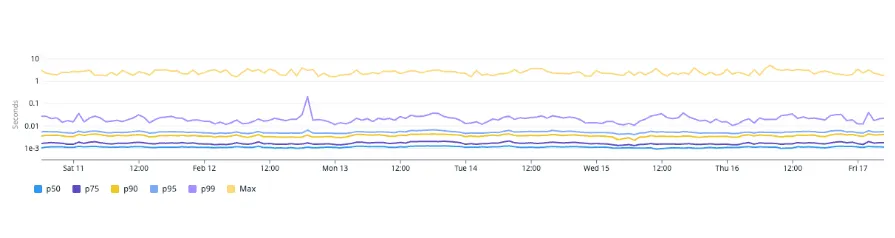
After identifying the issue with DNS resolution, our next step was to determine whether the root cause was a DNS server-side issue or a Node.js client-side one. We first checked our Grafana dashboards for NodeLocal DNSCaches showing request rates and latencies but found nothing suspicious. We also cross-checked other services running on different tech stacks (JVM, Python, Golang) to rule out the possibility of a server-side issue that would have affected all services. However, we did not find any traces indicating long DNS queries or TCP connections.
Let's attempt to fix this!
Attempt 1: Caching DNS Lookups
The first attempt was to try out `cacheable-lookup`, an npm package that caches DNS lookups. The package can be integrated into most HTTP agents for Node.js. It's important to note that cacheable-lookup is an ECMAScript modules (ESM) package. If you're using CommonJS (CJS), you'll need to use dynamic imports to import it. Intriguingly, when we integrated cacheable-lookup into the HTTP agents in our Node.js service within our Kubernetes cluster, we ran into some issues. We started seeing several "getaddrinfo ENOTFOUND" errors in Datadog, indicating that cacheable-lookup wasn't playing well with our Kubernetes cluster's DNS setup.
1Error: getaddrinfo ENOTFOUND
After some investigation, we discovered that cacheable-lookup uses dns.resolve to cache DNS results, which wasn't compatible with our cluster's DNS setup. So, we had to roll back to using DNS.lookup instead, which is what the default Node.js HTTP agent uses. For better or worse, adding another caching layer in a dynamic environment like Kubernetes, where pods are being added and removed frequently, would introduce additional complexity, requiring retry-logic as the DNS cache entries became invalid.

Attempt 2: Reproduce with Load Testing
Hey, we’re engineers, but we’re not perfect. We should have load tested our service first. But better late than never, right? 😅 At Wolt, we're fortunate to have an in-house service called wolt-load-test, which makes load testing a breeze. Using Gatling as its backbone, this service enables us to easily orchestrate and run load tests against our services. Plus, it can integrate with our CI pipelines for continuous load testing, which is pretty cool.
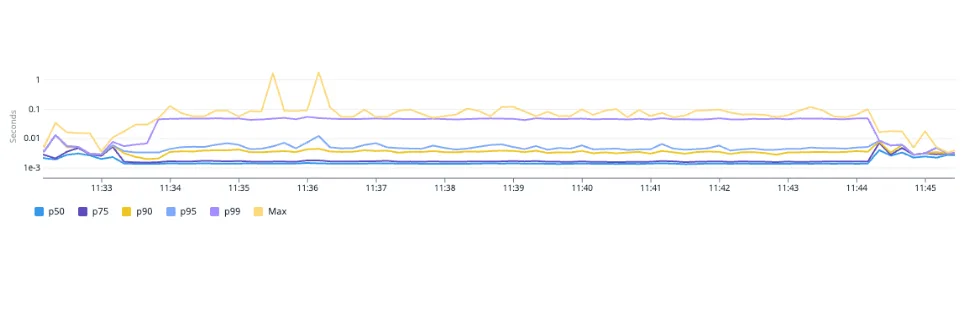
Interestingly enough, when we load-tested wolt.com, we didn't get the actionable results we were hoping for. This was most likely due to the much smaller scale of our development environment, having fewer pods and fewer DNS lookups. But that's okay - it's better to have load tested and ruled out potential issues than to have not tested at all.
Attempt 3: Fully Qualified Domain Name
The third time’s a charm, right?
Another method we tried was to reduce the DNS resolution latency in Kubernetes. We explored the power of having fully qualified domain names for upstream service endpoints. FQDNs provide complete domain names, encompassing all subdomains, which can reduce resolution times by requiring fewer DNS lookups. This is because the complete information contained in the FQDN allows DNS resolvers to directly resolve an IP address associated with the resource without the need for additional queries or lookups. With FQDNs, Kubernetes can intelligently cache the DNS records of our services, diminishing the need for repetitive DNS lookups and, ultimately, enhancing the overall performance of our services.
To implement this approach, we added FQDNs for some of our critical upstream dependencies, employing a format similar to this: upstream-service.production.svc.cluster.local. Optimistically, we tested this configuration and subsequently deployed it to our production environment. However, much to our surprise, the very next day we noticed a sudden spike in DNS lookup latencies.
Perplexed by this unexpected setback, we delved into the depths of debugging until we stumbled upon a tiny yet significant missing piece in our FQDN setup. It turned out that a tiny "dot" at the end of the FQDN was missing. This seemingly inconspicuous "dot" actually represents the root of the DNS hierarchy and plays a vital role in the structure of an FQDN. Consequently, we promptly corrected the FQDN by adding the missing "dot," transforming it to upstream-service.production.svc.cluster.local.
The absence of the trailing "dot" in the FQDN caused it to be interpreted as a relative domain name, which would be resolved within the context of the current DNS search domain. In other words, the DNS resolver would attempt to resolve the domain name using the local domain search rules before reaching out to the root DNS servers.
With the missing "dot" rectified, we eagerly anticipated a substantial improvement in our latencies. However, the results were not as remarkable as we had hoped, with only a marginal enhancement of around 1-2% in latency reduction.
Back to the drawing board.
Attempt 4: Thread Pool Work Scheduling in Node.js
After some time googling “DNS resolution + Node.js”, there were quite a few articles describing that DNS resolution was handled by libuv, therefore we decided to dig deeper.
Node.js relies on libuv for turning blocking operations into non-blocking ones. It abstracts I/O operations, such as file system interactions, network requests, and DNS resolution, and provides the event loop. By offloading blocking operations to the operating system, libuv allows Node.js to continue executing tasks without waiting.
Libuv introduces a thread pool in Node.js, consisting of a fixed number of worker threads. The UV_THREADPOOL_SIZE environment variable sets the thread pool size (default is four threads). These threads handle CPU-bound or blocking tasks that can't be offloaded to the operating system. However, it's important to note that when the thread pool is exhausted due to an overwhelming number of tasks, it can become a potential bottleneck, causing delays and impacting overall performance.
Given that wolt.com has plenty of upstream dependencies, increasing UV_THREADPOOL_SIZE was a natural thing to try out. We tried the values of 16, 32, and 64, load-tested them using wolt-load-test in development to ensure we didn’t introduce any negative impact on performance during high load. We chose to roll out UV_THREADPOOL_SIZE=64 to production to allow as much headroom as possible for these I/O operations. This was the single line of code mentioned earlier in the blog post, the results were impressive.
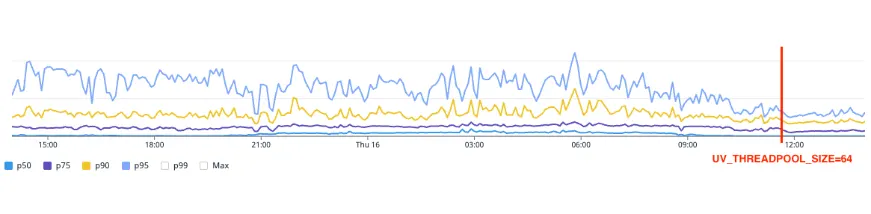
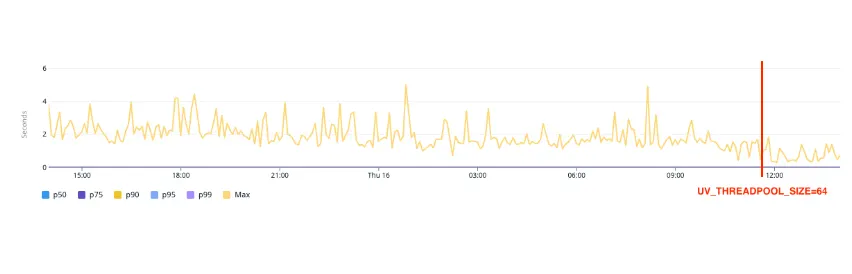
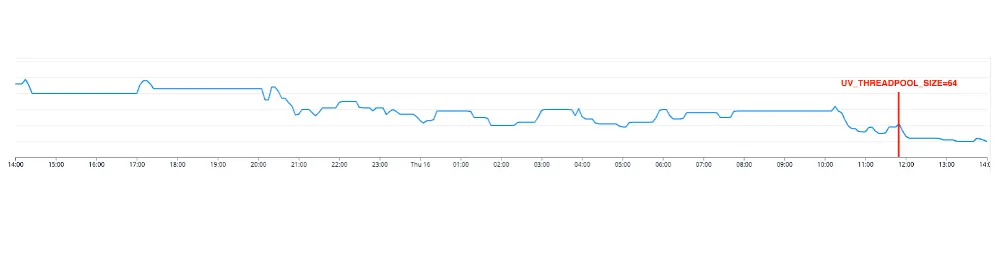
While it may seem tempting to increase the value of UV_THREADPOOL_SIZE to allow for more concurrent tasks in the libuv thread pool, there are potential drawbacks to consider. Increasing the thread pool size without considering system resources and workload characteristics can negatively impact performance. It can introduce overhead in terms of thread management, context switching, and synchronization, especially if the system's hardware resources are limited. Additionally, if the majority of tasks are CPU-bound rather than I/O-bound, increasing the thread pool size may not provide significant benefits and could consume unnecessary system resources. It's crucial to strike a balance and conduct performance testing to find the optimal thread pool size that maximizes performance without overwhelming system resources.
Conclusion
Improving the latency of wolt.com was a journey that required thorough investigation, experimentation, and careful optimization. By demystifying the Node.js DNS resolution process, we were able to identify a bottleneck and implement a solution that significantly improved the performance of wolt.com – all with a single line of code:
1UV_THREADPOOL_SIZE=64
Through monitoring and analyzing latency patterns, we discovered a correlation between spiky DNS.lookup times and request latencies. This led us to investigate DNS resolution as the potential culprit behind the performance issues. After ruling out server-side issues and exploring caching solutions, we decided to focus on optimizing the thread pool work scheduling in Node.js.
Our journey to improve wolt.com latency highlights the importance of thorough investigation, continuous testing, and experimentation. Performance optimization requires a holistic approach, considering various factors and potential bottlenecks. By understanding the intricacies of the underlying technologies and making targeted optimizations, we can provide users with a lightning-fast experience that meets their expectations in today's fast-paced digital world.