Tech
Fredrik Sannholm
Aug 24, 2022
Wolt loves open-source software

Here at Wolt we truly love open-source software. We’re a fast-growing company, building the rocket ship while riding it to allow our business to scale. This wouldn’t be possible without standing on the shoulders of giant open-source projects. Almost our whole tech stack is based on open-source software, most notably on the data engineering side.
We’ve adopted both established staples of the industry and up-and-coming projects that we can help become successful through our own contributions.
To mention a few of the more mature projects (which I define as projects offered as managed solutions by multiple vendors) we have in use:
Open-source project | Use case |
Driving our change data capture (CDC) data ingestion pipelines | |
Our main orchestrator for batch data processing | |
Prometheus, Alertmanager, and Grafana | For monitoring and alerting |
Some less mature open source projects (which are still full-fledged products, but haven’t achieved industry standard status yet) that we use and have contributed to include:
Open-source project | Use case |
Our data catalog | |
Our orchestrator for machine learning workloads | |
Powers our machine learning model deployments |
Wolt’s own open-source projects can be found under our woltapp Github organization.
There are several reasons for why we really like open-source projects, and trust them as part of our tech stack. For one, the more established technologies, like Postgres, Kafka, Prometheus, are considered to be the best-in-class in their respective fields. Open-source projects have a tendency to produce very high quality projects, and help to build a community around the technology that drives the tools to higher levels, beyond what’s possible with proprietary solutions.
Open-source projects tend to be offered by multiple providers (if opting for a managed service) allowing us to be flexible about where we spend our precious infrastructure efforts and budget. Certainly many of the more established technologies we use are acquired as managed services (for example, Postgres databases on AWS and Kafka clusters on Aiven), but a large majority of the tools are self-hosted (made possible by our rock star infrastructure teams here at Wolt 💙). We usually pick this path if there are no SaaS solutions available, which is the case, for example, for very niche or new solutions. All of this means that we’re not locked in to a single vendor or provider, and can pick the tools we want instead of what’s available.
As said, while we utilize many industry-standard open-source projects, we also make bets on less established projects. The focus of this article is going to be on how we at Wolt contribute to open-source projects, and some general rules we follow when selecting these less mature projects into our stack.
Why we contribute to open-source projects at Wolt
We want to give back to the community for providing us with these awesome tools
The spirit of open-source is primarily that the community contributes to the project and that it is allowed to use “for free”. As a for-profit company utilizing great, “free” software, we see ourselves obliged to contribute back where we can. While we don’t necessarily imagine ourselves being able to improve on the Postgres codebase, we do try to contribute to these well-established projects in other ways, for example by reporting bugs and helping troubleshooting, or updating documentation when we notice issues.
We want to add functionality that we need, and that others can benefit from.
In other, less mature projects which are still under more active development feature-wise, and closer to the core competences of our teams, we’re more than happy to work on request for comment (RFC) documents and help implement features that are important to us and also benefit the community. It’s a win-win for everyone involved!
Contributing to the project adds momentum around it, which is in our favor in the long run
Adding features that we want, or by simply helping the core developers fix issues that we run into, helps the project become better and builds momentum around the project and helps build the community. By contributing to a collaborative and constructive community (through thoughtful and professional interactions), we do our part of making the community a more welcoming place for others. This hopefully helps create a positive feedback loop, making the tool even better for us and everyone else as well.

It’s important for us to understand how our tools work, so we know how they scale and how to fix them, if needed.
Being able to take a look under the hood of the core components of our stack is important to build trust towards them. With rapid growth comes scaling issues and driving the tools at the edge of their limits isn’t uncommon. We therefore need to know that the architecture and codebase is built in a way that it scales with us and that we can go in and fix it if needed.
Networking with other developers around a tool everyone is passionate about is a lot of fun!
Collaboration is fun, and sharing ideas with developers from other companies about a project you feel passionate about is extra fun! There is a certain excitement to being able to learn and share with others, and scaling one’s own work while giving back.

How we pick open-source projects — betting on the right horse
Some open-source projects are industry staples, and the selection process is quite straightforward, based on the system we’re building, the scale we’re anticipating, and the team’s skills. However, when we select a less mature project for our stack (one that we might need to host ourselves and make code change contributions to) we have a slightly more thorough selection process — a due diligence process of sorts, but for software tools. At Wolt tooling choices are made on a team level, but for larger deployment projects we consult our infrastructure teams, as well.
We’ve here listed some basic rules-of-thumb that we follow when evaluating adding an open source project to our stack. While the focus might be more on deployable tools, some of the points can also be applied to libraries. None of the rules are deal breakers in themselves, but we’ve tried to group them in order of importance.
Priority 0
Does the tool fit our current infrastructure?
If you need to set up a lot of support infrastructure around the deployment to get it running, the size of your deployment project grows to a whole other level of complexity. Preferably the tool would integrate well with your existing infrastructure for things like monitoring and authentication for instance.
Does the architecture and deployment make sense?
Tools and projects are designed for different types of organizations, especially in terms of the surrounding infrastructure and architecture. A tool designed for a multinational corporation will likely be built in a different way than a tool aimed at small developer teams. It’s therefore up to you to evaluate if the architecture of the tool will fit your organization.
Is the deployment maintainable with your resources? Will it be able to scale (in a very broad sense of the word) to the level you’re operating at now and in the future? Furthermore, you should ask yourself if the architecture signals credibility; are the design decisions sound?

Attention to security
The level of security you need from a tool will vary widely depending on the context, and it’s important to remember to make your own list of requirements when it comes to security. If the tool is meant for users to log in to, does it support role-based access control (RBAC) and can you connect it with the identity provider that your organization is using? Is the API properly secured and does it provide proper logging of access and actions? Does the backend allow for ephemeral credentials to, say, databases?
Is the state of the documentation acceptable?
If you’ve answered the questions above, you’ve probably had a look at the documentation by this time. The documentation says a lot about the maturity and level of ambition of the project you’re evaluating. Poor documentation should be considered a red flag. Some things to check for are:
Are the concepts of the tool described, and does it include an API reference?
Does it include clear examples and tutorials on getting started with the tool as well as explaining the more advanced use cases? Is it easy to get a local instance running with the help of the documentation?
Does it explain different deployment models into different environments?
Priority 1
Are the feature requirements reached (or within reach)?
It goes without saying that the tool should be fulfilling the requirements you have on it, but often the tools don’t tick all your boxes feature-wise. Also, when comparing two competing projects, you might often find that both of them are lacking in different areas, and there’s a tradeoff to be made when choosing one over the other.
The question is then: is the project within reach of ticking all your boxes? Maybe the missing features are on the roadmap already or there’s a popular feature request for it? Or maybe the foundation is in place and you could see yourself contributing to make the feature a reality? On the other hand, maybe you find out through discussions with the core maintainers that they’re not even looking to develop the tool in the direction you need it to be?
Is the backing organization/community credible?
The previous point is also related to your trust in the core development team, and the community around the project. If you’re going to make a bet on a project, and include it into your tech stack for potentially years to come, you’ll want to make sure that the project is in good hands and will be receiving updates and new cool features.
This is why we always make an effort to engage with the core developers when evaluating a project. We want to get a feeling for how they see the future of the project (see previous point) and if we can see ourselves working alongside on the project as contributors.
How is the community?
This point is also related to the previous one, and can sometimes be overlooked or judged too quickly. As Pedram Navid points out in his love-letter to the open-source project dbt, it’s not always about the size of the Slack-community. A Slack workspace that has grown too large quickly becomes unmanageable and causes all channels to become endless wells of questions without answers.
So instead of staring at the member count in the project Slack channel (or equivalent), try to evaluate what percentage of the questions are getting answered and the quality of those answers. And if the project doesn’t have a Slack channel, try checking the issue in Github. Do issues and questions get a response from others than the core team? Also don’t hesitate to ask questions yourself if you run into issues with your proof-of-concept, for example. This gives you first-hand experience on the helpfulness and responsiveness of the community.
As stated above, the size of the Slack community is not the best indicator of the quality of the community around a project. Other, less obvious signs of a strong following behind a project include community developed plugins/addons, number of PRs from contributors outside the core team, and articles written/meetups help about the project.
Priority 2
Set up a proof of concept and get a feel for the product
The documentation seldom covers all aspects of the product, and setting up a simple proof-of-concept of the deployment is always recommended. You might run into issues you couldn’t foresee otherwise, and maybe the features you need don’t work like you expected. Spin up a local deployment, and try out the functionality.
If the tool isn’t easily testable locally or if the documentation doesn’t cover how to get started quickly, it might be considered a red flag.
Can we contribute back?
After all the above has been checked, you have most probably started to form a view on whether this project is something you could see yourself contributing to. Is contributing made easy with clear contribution guidelines, generally good code quality, and by welcoming contributions and questions from newcomers? Is the codebase written in a language your team has expertise in? Remember, there are several ways of contributing, and contributing is truly a win-win situation for everyone involved!
How do we contribute at Wolt
Depending on the project we have identified several ways we can contribute back to open-source software:
Write RFCs in collaboration with the core development team
Make bug reports and help troubleshoot them. Respond to open issues with our own findings.
Implement features that we need, and that can benefit others as well.
Make smaller contributions, like feature requests and documentation updates.
Engage with core developers and give feedback on the tool. This we always try to do, to get a sense for the org behind the tool (see below).
Hangout in the Slack room, keeping an eye on issues. This is quite rare, but it happens if the community is really good.
Success story: Datahub
When our data engineering team at Wolt started looking for a data catalog to capture lineage between our data tables and processing, we set out to find an open-source option from the get-go. At the time the data catalog scene was very different from today, and we were only able to find one candidate that seemed to fulfill our requirements: support for lineage tracking and visualization, extendable metadata model, and agnostic to the metadata type it was able to ingest.
With the help of our infrastructure team, we did our best to put together a proof of concept, but soon realized that even though the tool met many of the requirements it wouldn’t be a good fit for us in the long run. The main issue was incompatibility with our Kubernetes based infrastructure, which made the tool difficult to maintain.
It was around this time that we stumbled upon Datahub. It was still a project maintained by LinkedIn, and the community was quite small, but it seemed promising: a modern tech stack with Kafka as a message broker, Kubernetes-native, lineage tracking, and sensible architecture that promised to support “LinkedIn scale”. It lacked some features, like proper access management and a sensible abstraction layer for the ingestion of metadata, but we gave it a shot.
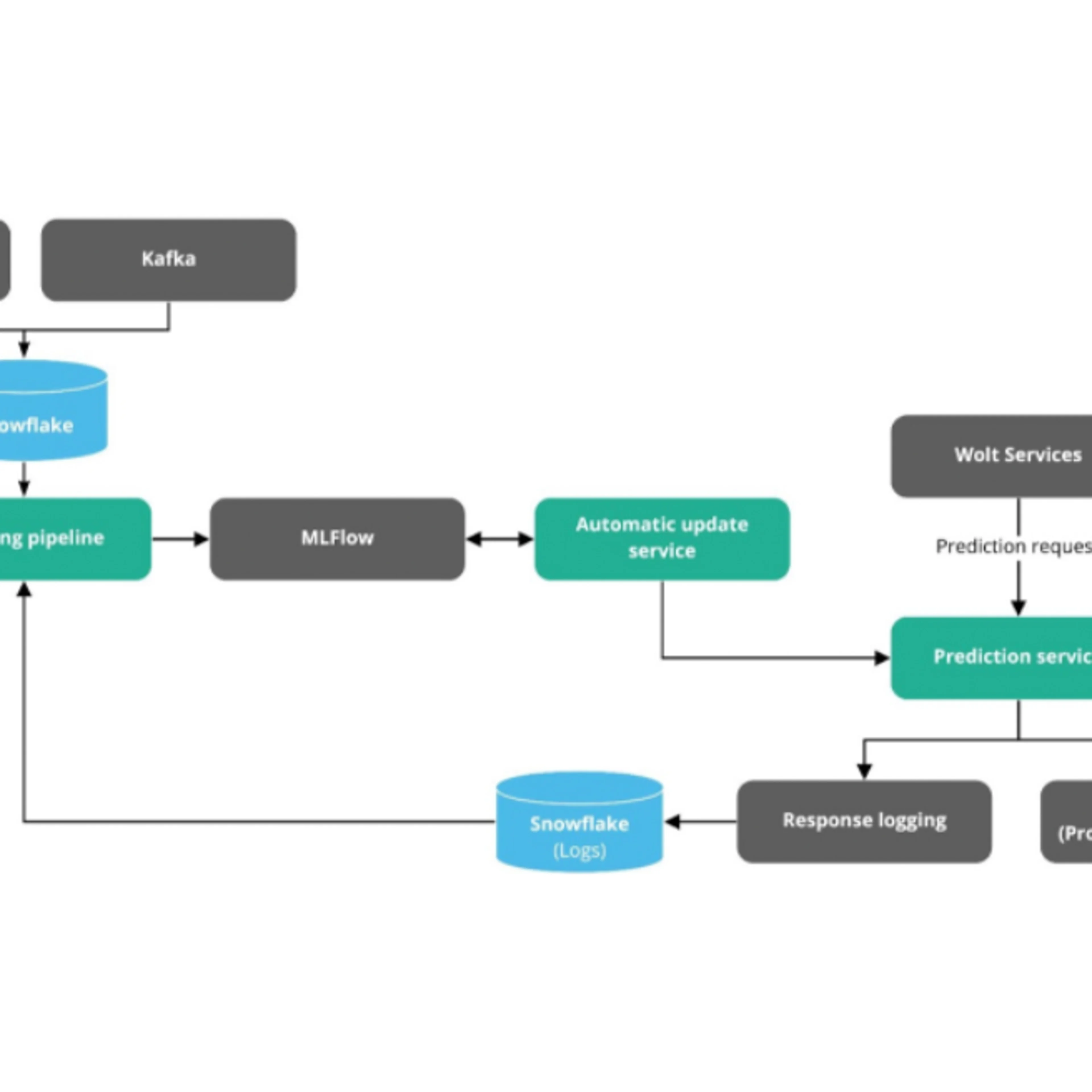
Modifying the public helm-charts to fit our needs took a while, but at least we knew the technology we were working with and could figure out how to configure the tool. We also built an abstraction layer in front of the Kafka-based ingestion pipeline to simplify the process. Throughout this initial phase we got great help from mostly the core developers, who eagerly helped to answer our questions and read through our debug logs. After getting Datahub deployed, we quickly set up pipelines to ingest metadata from our data warehouse in Snowflake, our service databases, and Kafka-based data pipelines. It was at this point that we knew that, even though the tool had its gaps, we could make it work for us for what we needed it to do.
So we started contributing to Datahub to fill these gaps. We had a need to add tags to our representations of Snowflake-tables in Datahub, to represent the different sensitivity levels of the columns. For this reason we first engaged with the core team to develop an RFC to introduce the topic of tags in Datahub, and later we helped implement the feature itself. Next, we needed to bring our Airflow workflows and tasks into Datahub, as Airflow orchestrated a majority of our data pipelines at the time (and still does). There was preliminary work on the topic, but we helped finalize it. After that we contributed and pushed for security improvements, and helped improve the ingestion framework the core developers later made available.
By this time, we were quite acquainted with the Datahub codebase and having managed our own deployment for a while, we were able to help out with answering questions around the Slack workspace here and there. The community had already started building, but it really took off when the team behind Acryl Data took over as main contributors of Datahub. Even though the company is a for-profit organization and offers a managed Datahub service, it has done a great job balancing between the open-source and demanding, high profile customers. The open source project has in the last nine to twelve months seen some remarkable improvements, and to be honest, we’re still playing catch up to take them all into use. The popularity has exploded, and even though the data catalog space has exploded recently, Datahub remains one of the most popular ones. We continue to reap the benefits of our contributions and networking we did in the early days of deploying the tool.
To conclude, at Wolt we’re huge fans of open source software. Especially our data and machine learning engineering stack consists in large part of open-source projects like Airflow, Datahub, Flyte, and Seldon-core. In this blog post we talked about how we think about contributing to open source, and presented our framework for picking projects to be added to our stack. We strongly believe in the long-term benefits of adapting and contributing to open source projects, and we’ll continue using and supporting them.