Engineering
Tero Laitinen
Jun 9, 2023
From Polling to WebSockets: Improving Order Tracking User Experience

Where is my order? Is the app stuck? Even when everything else in an application is polished, the user experience might be far from delightful if the information on the screen rarely updates. Displaying up-to-date and often updating information on an application view inspires confidence in the quality of the product and the prospect of getting what you ordered.
In 2020, our consumer apps (iOS, Android, and web) still polled the backend services for order tracking information. Since then, we have rolled out many WebSocket-based services, which push state updates to connected clients, also in non-consumer apps. One of these services is consumer-events, dedicated to serving the Wolt iOS and Android apps and our website at wolt.com.
Our load-balancing infrastructure did not initially support WebSockets, so we first experimented with Socket.IO, a multiprotocol library for bidirectional low-latency communication. After a proof of concept involving delivering push notifications through Socket.IO, we could switch to plain WebSockets for greater simplicity and interoperability with mobile clients.
Now, our backend services push order tracking and group order state updates through the service consumer-events to consumer clients in addition to notifications. As a result, we can refresh client app views frequently and with low latency. Ensuring satisfying user experiences is our top priority, but our engineers also enjoy reduced server loads due to less polling, enabling us to better serve our rapidly growing user base.
Proof of Concept: Delivering Notifications Using Socket.IO
Implementing a WebSocket-based service on top of our existing load balancer and ingress controllers had an additional hurdle in 2020. We used Classic Elastic Load Balancer (ELB), which does not support WebSockets. Switching to receive all traffic through Network Load Balancer (NLB) was not an option at the time because our ingress controller redirected HTTP to HTTPS using the HTTP scheme header set by ELB. Such redirects help keep secure users and browsers that insist on insecure connections. The Application Load Balancer (ALB) supports WebSockets, but may be more expensive and slightly less performant than NLB. Also, we did not need its advanced routing features, so we decided to add a new NLB-based ingress controller.
To move forward with other parts of the project, we experimented with Socket.IO's long-polling transport method, which worked with regular HTTP and was thus compatible with our infrastructure. The only configuration tweak required to support long polling with session-state tracking in the backend (see Socket.IO load balancing) was cookie-based affinity in our ingress controller. We scoped the proof of concept to deliver notifications through the Socket.IO channel to wolt.com. If something had gone wrong, the worst-case blast radius would have been small.
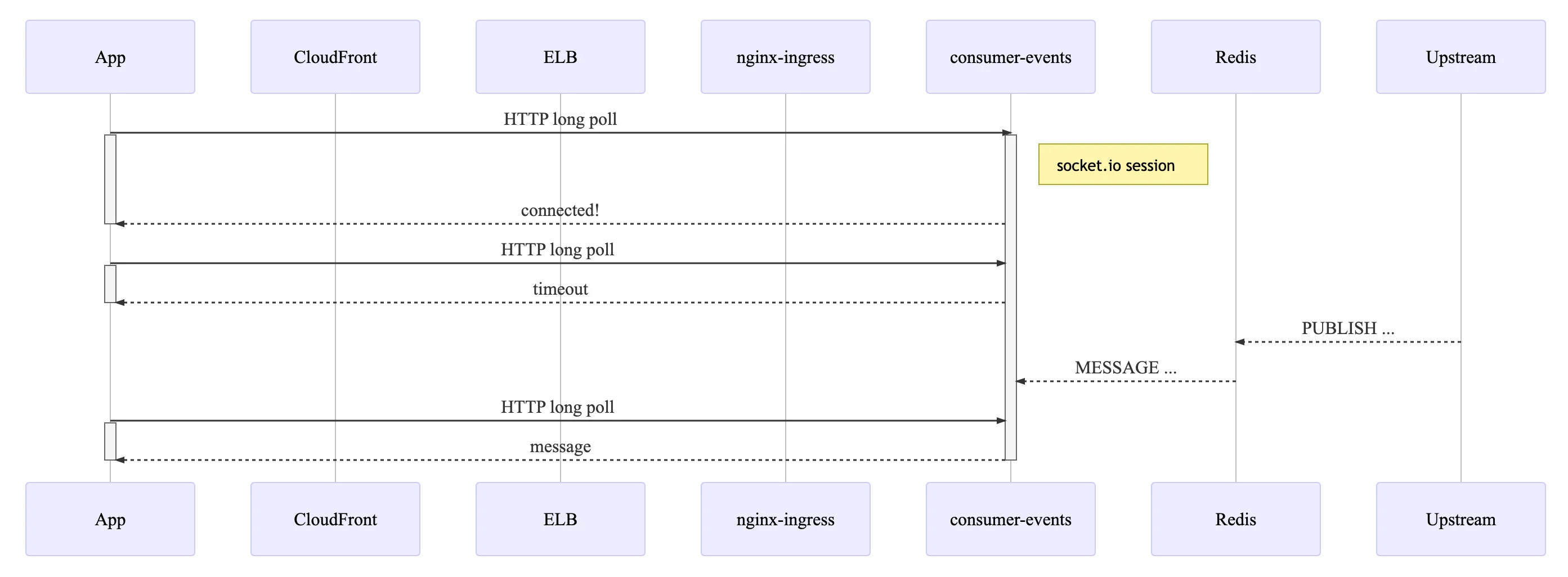
In the service-to-service communication part, we considered two alternatives, Apache Kafka and Redis, and opted for the latter, which was less complex yet fit for the task. We leveraged Redis' Pub/Sub messaging paradigm to implement a service-to-service message relay between the new service consumer-events and other backend services. In this initial implementation, we employed Socket.IO's Redis adapter, which uses a shared PUB/SUB channel in a single Redis instance for all messages.
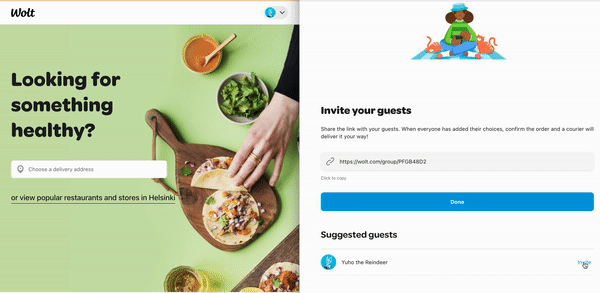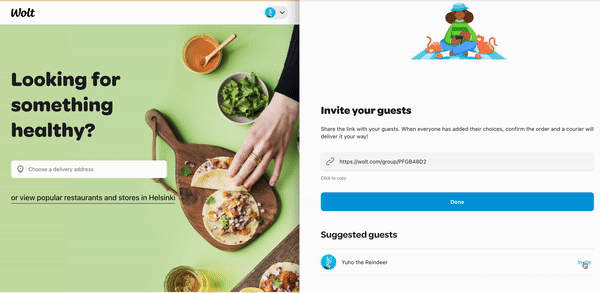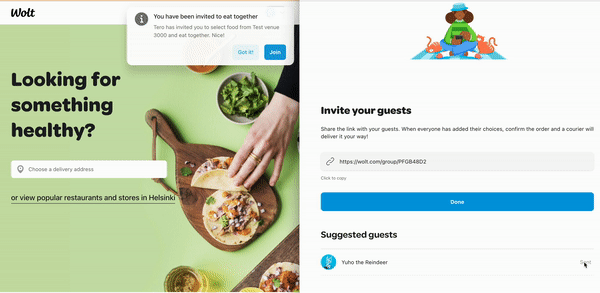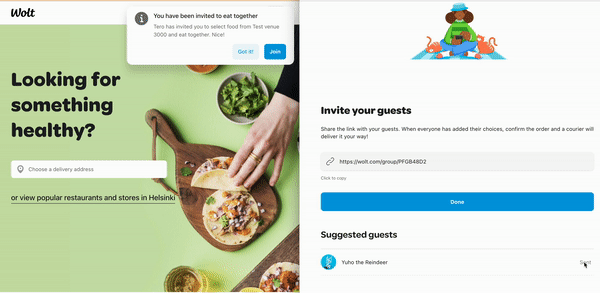
Inviting other users to join a group order was a convenient way to trigger a push notification ("X invited you to order together!") from one client session and test how another client session handles it.
After a gradual rollout to our web client users, we considered including mobile clients in the experiment. While a native Socket.IO library existed for mobile platforms, we decided to wait until our infra could handle WebSockets and migrate to using them directly without Socket.IO. Switching to Socket.IO’s WebSocket transport was an intermediate step that would eventually allow us to drop the dependency on the library.
WebSocket-based State Updates
Our new ingress WebSocket-compatible controller used AWS Network Load Balancer (NLB) instead of ELB, allowing us to enable Socket.IO WebSocket transport. By default, the Socket.IO client library establishes the connection with the HTTP long-polling transport and allows passing the authentication JSON Web Token (JWT) in the Authorization request header. After rolling out Socket.IO’s WebSocket transport, we added a WebSocket server powered by ws, the Node.js WebSocket library in the same service. By running both Socket.IO and ws, we could migrate the clients without disruption from Socket.IO before sunsetting it. The HTTP protocol upgrade mechanism does not permit including the Authorization request header, so we modified the client to send the authentication information in a WebSocket frame when we switched to the plain WebSocket server.
We use the ES256 algorithm to sign and verify JWTs. Asymmetric cryptographic algorithms are computationally more demanding than symmetric ones, so we wanted to ensure that the WebSocket server, which uses the library jsonwebtoken, could handle a sudden burst of incoming connections without problems. Measuring the server memory usage was equally important. Surprisingly, the initial WebSocket server implementation became CPU-starved and could not execute WebSocket PING timers fast enough, resulting in connection timeouts.
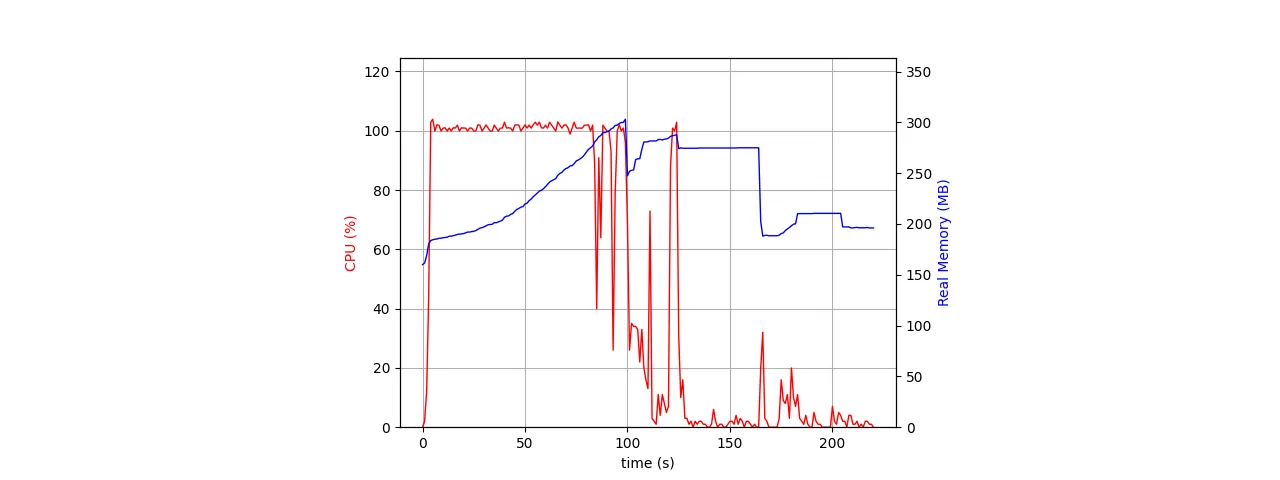
We improved our server's scalability by introducing backpressure in form of a queue to hold JWTs waiting for verification and processing a fixed number of JWTs per one cycle of the Node.js' event loop. After curbing the latency of the event loop, WebSocket PING timers could run often enough, and no connection timeouts occurred. The measurement revealed the server was sufficiently memory efficient, peaking at just over 700 MBs when handling a burst of 10000 connections. Subsequent versions of the library jsonwebtoken have since improved the JWT verification efficiency, so adding such a queue to throttle JWT verification is likely no longer necessary.
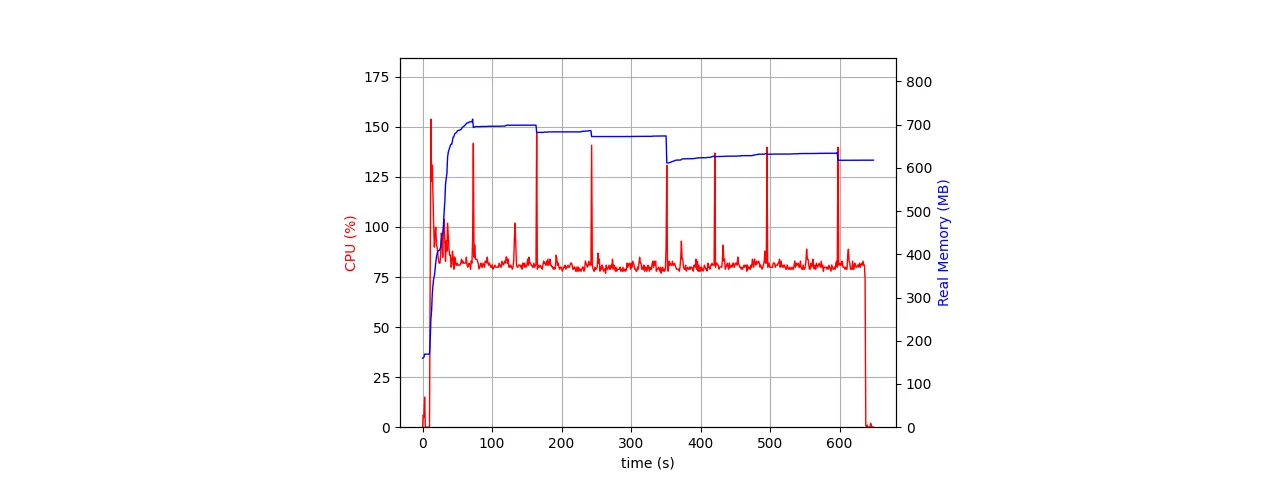
A single Redis instance can relay messages at high throughput, but we decided to future-proof the message relay architecture by being able to scale horizontally with Redis Cluster. Each Wolt user account has a dedicated PUB/SUB channel starting with the prefix “user_”. We wanted to avoid broadcasting all messages to all service pods, so instead of subscribing to all PUB/SUB channels with PSUBSCRIBE, each pod maintains subscriptions to connected users’ channels with SUBSCRIBE and UNSUBSCRIBE. Redis memory usage increases linearly with the number of active users, and the channel subscription logic is more complex than with PSUBSCRIBE. However, service in-cluster network traffic and CPU consumption are bounded by what is required to serve connected clients. We can further increase the overall message throughput by switching to a Redis cluster, exceeding the limits of a single Redis node. After verifying a JWT and extracting the user ID, a WebSocket server pod subscribes to the corresponding PUB/SUB channel. When the Redis instance acknowledges that the PUB/SUB subscription is active, the WebSocket server sends a WebSocket frame that informs the client application that the message pipeline is ready.
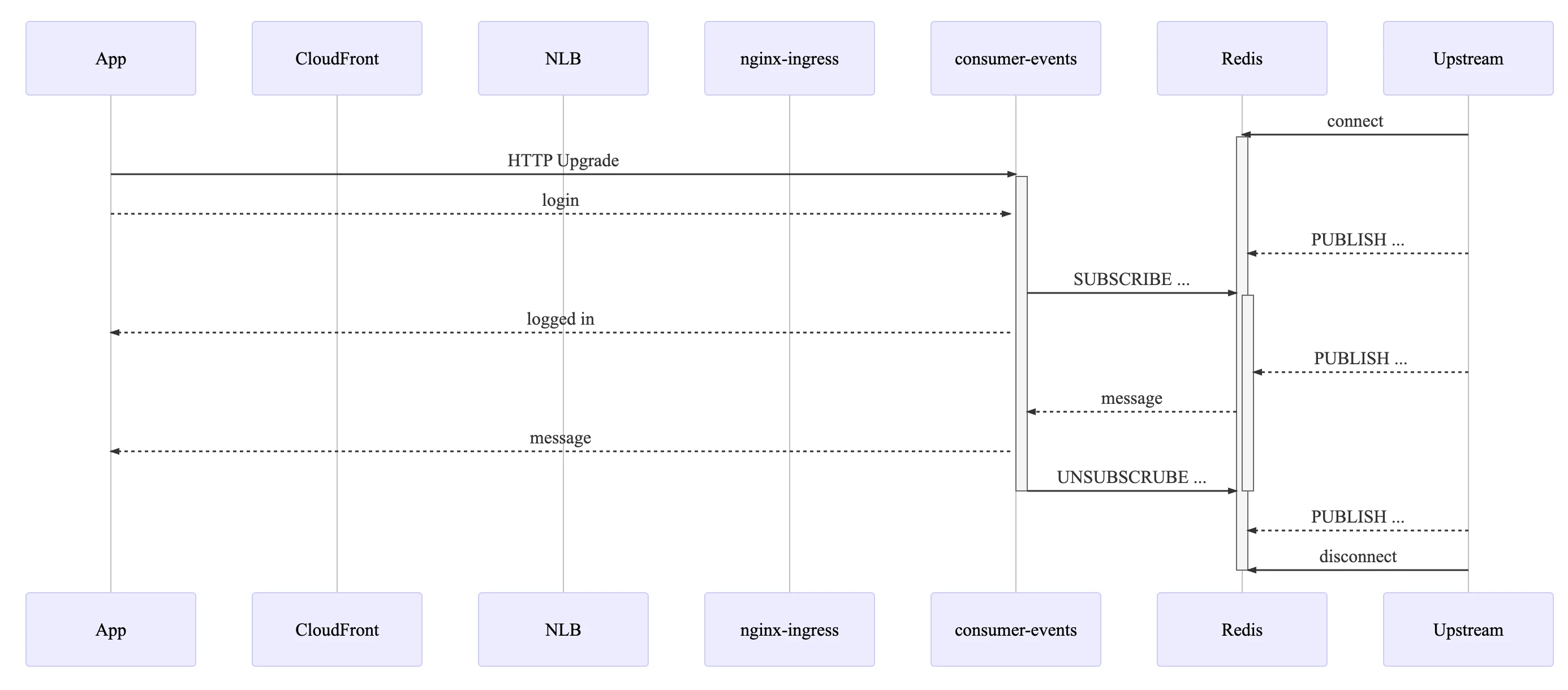
Redis is a critical part of the setup, so we employ a highly available Elasticache Redis instance with Multi-AZ failover. If the primary node becomes unavailable, the hostname will quickly resolve to a newly promoted replica. We tested one variant of this failure scenario by bringing down the primary and checking that the WebSocket server immediately reconnects. However, we failed to account for the case where the Redis server does not explicitly terminate the TCP connection. We got to test this case in production. The first Elasticache Redis instance created for the proof of concept did not have Multi-AZ configured. When we enabled it, the primary Redis node disappeared without saying bye. The WebSocket server no longer received any PUB/SUB messages through the connection but did not terminate WebSocket connections, causing a short order tracking UX degradation. The Redis client library redis had long connection timeouts by default and disallowed PINGs during a subscription, so we switched to ioredis, which did not have such a restriction. We could then modify the Kubernetes liveness probe handler to PING the Redis instance and ensure that any pods without a working Redis connection would get replaced.
Monitoring service health and alerting when potential issues begin brewing is essential to reaching many nines of availability and offering the best possible user experience. The WebSocket server exposes the connection count and the number of relayed messages to Prometheus. We aggregate data from Prometheus and CloudWatch to DataDog and can set up appropriate alerts there. One of these alerts helped us notice the issue during the Elasticache Redis configuration change. Purpose-built Grafana dashboards also help form a quick overview of service health.

Resource consumption varies daily and grows steadily. Additional pods can absorb increased loads, but automatically figuring out a suitable number of replicas using the built-in Kubernetes metrics is challenging. The service's resource utilization is not CPU-bound, so CPU-based horizontal pod autoscaling (HPA) is unsuitable. The system might run out of memory or sockets, depending on the configuration. Besides resource consumption, many WebSocket connections in one pod might cause fluctuating server loads elsewhere in the system in case of an uncontrolled server termination, as the disconnected clients would all switch to polling. Targeting a reasonably low number of active WebSocket connections per pod, in the order of thousands, may thus be justified. We're currently experimenting with scaling the service replicas using Kubernetes-based Event-Driven Autoscaler (KEDA), but, for the time being, we manually bump the number of replicas when an alert associated with the number of active WebSocket connections triggers.

Client Implementation Considerations
WebSocket connections are for authenticated users, so the client sends the authentication JWT in a WebSocket frame after connecting. An authentication JWT has a relatively short validity time, so a long-lived WebSocket connection may outlast it. In this case, the client should send a renewed JWT before the previous one expires. Otherwise, the WebSocket server will terminate the connection.
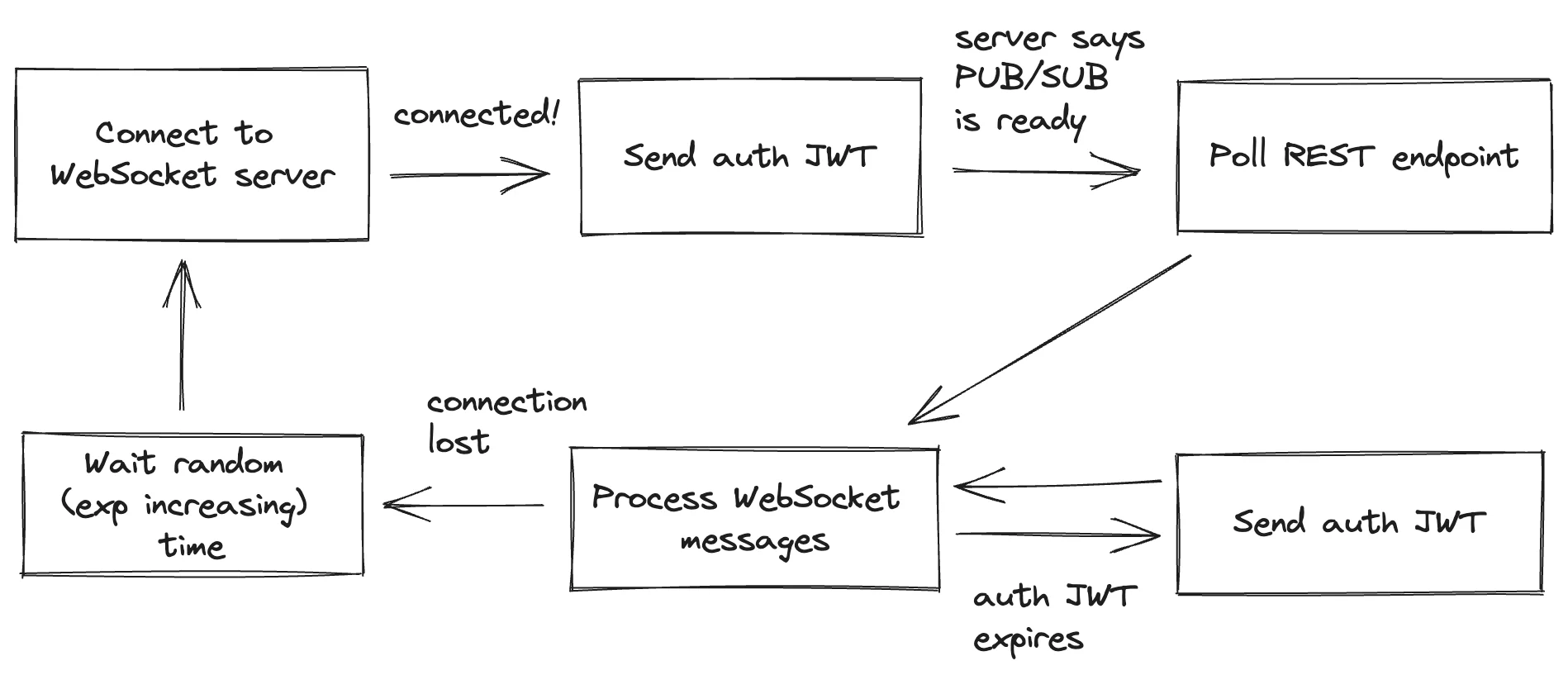
After a client connects to the WebSocket server, it should continue polling the REST endpoint until the WebSocket server acknowledges that the message pipeline is ready and then once more. The WebSocket server sends a WebSocket frame indicating that the service is subscribed to the user’s PUB/SUB channel. Polling once more after receiving the frame ensures that the client has a consistent snapshot of the state before processing any partial state updates streamed through the WebSocket connection.
When the WebSocket message relay becomes active, polling the RESTful HTTP endpoint ensures no data is lost. Still, a race condition is possible: WebSocket messages may replay state updates that assume an earlier version of the state than the snapshot the client fetched. Adding timestamps to the data returned by the RESTful endpoint and to WebSocket messages would allow skipping state updates older than the snapshot. However, this is not bulletproof because the client could receive an old snapshot due to reordered network packages and resends. The client might have already updated the local state to a newer version using the data stream from the WebSocket connection. Restoring the local state to the snapshot could revert some partial state updates. Order tracking state updates are relatively rare compared to the delicate timings involved in a potential race condition, so the likelihood of this happening is minimal. Even so, the WebSocket protocol we use for partial state updates always overrides a part of the client state instead of aggregating the previous value to produce the next state, so the UX impact would also be insignificant.
The browser WebSocket API does not expose sending PING frames to the server. So, if it had been critical to detect quickly that the server had silently disappeared, we could have implemented custom heartbeat messages on top of WebSocket text or binary frames. However, this scenario is improbable in our case, and we rely only on server-to-client PINGs.
When the WebSocket connection terminates, the client should resume polling, but only after a randomized (and exponentially increasing) delay to avoid creating a polling storm that could threaten service stability.
Conclusions
By starting with a polling architecture, we could focus on core business features while offering an excellent order-tracking user experience. When we had fewer active users, clients could poll the state more often without straining the backend. Now we operate at a scale where relying only on polling is impractical.
After a proof of concept of delivering notifications to wolt.com through Socket.IO 's long-polling transport, we were confident to build support for WebSocket-based services in our ingress controllers and a WebSocket-based service that would serve all consumer clients.
Maintaining user-specific PUB/SUB connections between a Redis instance and the WebSocket servers scales to many users. As an unexpected dividend of this technology choice, upstream services may use Redis transactions to implement message-triggering logic, for example, to skip duplicates.
Work remains to configure the horizontal pod autoscaler to adjust server capacity based on WebSocket connection count. Controlled pod shutdown also has room for improvement as it disconnects all connected clients simultaneously. If we need support for unauthenticated WebSocket connections, it would require some refactoring and security considerations.
Enhancing the initial polling-based state synchronization through long-polling to WebSocket-based event streaming has significantly improved the order-tracking user experience and reduced server loads. The initiative has also unlocked WebSockets for other services and applications, so now we can offer an even better experience for all users of our platform.
The next time you order with Wolt, peek under the hood and see how it all works. Do you have ideas on how we could improve? Or would you like to know how the rest of it works? In either case, we'd love to hear from you and have you on our team. Please check out our open jobs 💙