Tech
Ibbad Hafeez, SRE Competence Lead & Helena Anttila, Head of Tech Support
Jan 16, 2024
On-Call at Scale: How we do on-call engineering at Wolt

In most tech companies, on-call engineering stands as the invisible backbone ensuring seamless operations and prompt resolution of potential disruptions to the business. On-call engineers are the first responders to any emergencies – whether it’s during or outside the regular working hours. They’re dedicated to maintaining the smooth functioning of operations.
At Wolt, the significance of on-call engineering goes beyond just operational efficiency. It's about crafting a system that ensures maximum reliability and minimal disruption for our users. This way we can deliver anything to our users as fast and efficiently as possible, and create what we call a Wolt-grade user experience.
In our previous blog post, we talked about our Incident Management Process and how our Tech Support and On-call Engineering work together in critical incidents. This time, we’d like to take you through our approach to building and improving our on-call process and how it's evolved as we’ve scaled to serve millions of customers in 25 countries.
Our unique approach to on-call engineering at Wolt
Traditional industry practice is to have dedicated on-call engineers for each team or service. In contrast, at Wolt we've opted for a pretty unique solution. In our model, a single 24/7 on-call engineer oversees our whole platform during their shift. This includes monitoring over 300 services across the entire engineering organization!
Being on-call for 300+ services might sound a bit scary at first, but in practice, it’s not due to how on-call works at Wolt. The on-call model originates from our early days when our engineering team wasn’t big enough to support multiple on-call rotations. As we’ve grown, instead of expanding the on-call rotation, we’ve empowered the single on-call team to operate at the same efficiency as we scale. Let’s dig into the ins and outs of how this works in practice.
On-call is flexible and voluntary
Being on-call as an engineer is voluntary and compensated on top of one’s regular salary.
In practice, to ensure continuous 24/7 oversight and timely response for any business critical issue without overwhelming our on-call engineers, we run two shifts per week. These shifts operate between Mon-Fri and Fri-Mon. Each shift has 64 hours of on-call responsibility outside of office hours and is covered by one on-call engineer. In case of special needs, more on-call engineers can be requested to ensure better support in case of any issues. The shifts are booked a few months in advance with an option to make changes after booking the shift, to accommodate for personal changes. To make sure that on-call engineers aren’t overbooked and that they have enough time to rest between shifts, the general practice is to have one shift per on-call engineer per month at most.
Compensation for these shifts is structured to recognize and value the dedication of our on-call engineers. That’s why on-call engineering is always paid for on top of one’s regular salary. Additionally, any escalations to engineers who are not on-call and need to jump in to resolve critical issues outside of their regular working hours are compensated 2x or more for those hours, depending on the timing of the incident.
Any engineer is welcome to join on-call
On-call engineers don’t need to be domain experts or very senior engineers.
Joining the on-call team isn’t constrained by specific prerequisites. Any engineer from our diverse teams can opt-in. We believe this fosters a culture of shared responsibility and is a great way for our engineers to develop and learn new skills.
When joining the on-call team, new joiners are paired with an onboarding buddy from the existing team who supports them throughout their onboarding process. The onboarding process can start any time during the year, depending on the preferences of the new joiner. To ensure the high quality of on-call at Wolt, our onboarding is quite comprehensive and takes up to several weeks. It includes reviews of past incidents, common scenarios, critical services, alerting practices, and hands-on exercises like mock incident trials and on-call playbook walkthroughs.
The onboarding also includes at least two on-call shifts where the new on-call engineer is the primary on-call person backed up by another on-call engineer. This gives a chance for new on-call engineers to practice their learnings to handle actual incidents with the help of a more experienced member of the on-call team. Once both on-call engineers are confident with the performance, onboarding can be concluded.

Making on-call efficient as we scale
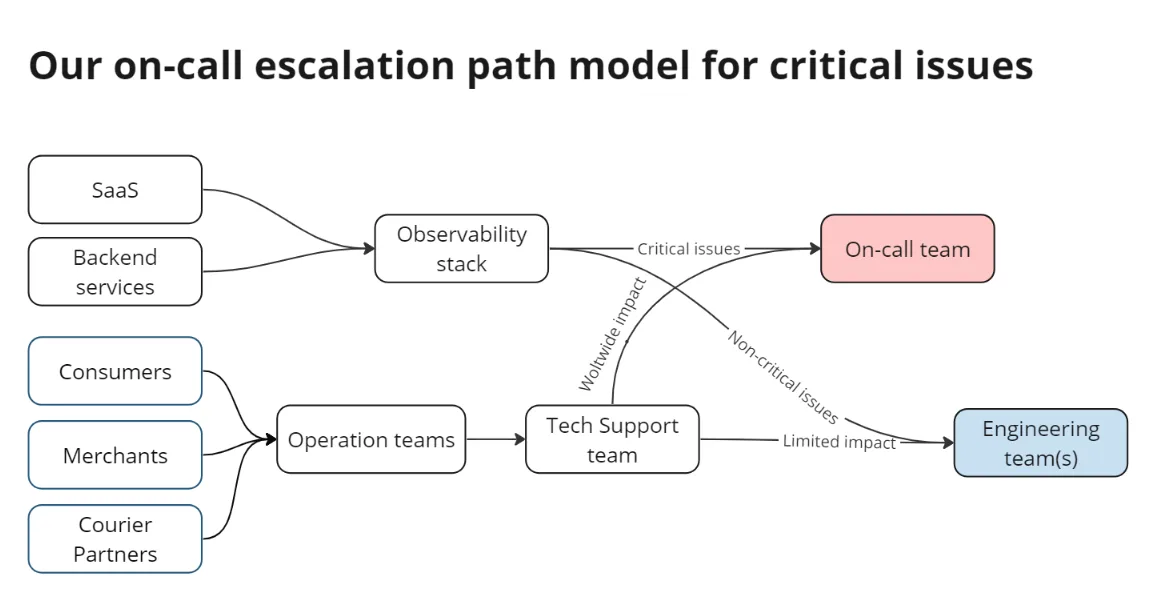
On-call responds to business-critical alerts using the documentation and tooling provided by engineering teams to resolve possible issues. In case of unexpected issues, engineering teams, and subject matter experts help to resolve them.
The efficiency of our distinct on-call model is made possible by the robust documentation and tools provided by our engineering teams. We rely heavily on service runbooks which contain detailed information about service functionalities, criticality, alerts, disaster recovery methods, CI/CD, security guidelines, past incidents, and more. These runbooks serve as a crucial resource, benefiting not just on-call personnel but the entire engineering team to understand the functioning and criticality of any given service.
To ensure focused attention for our on-call engineers, we’ve also implemented a process for differentiating business-critical and non-critical alerts:
Business-critical alerts | Issues that have a direct impact on Wolt’s core business, for example, disruptions to customer-facing applications or our courier platform Highest-priority alerts that must be resolved as soon as possible → immediate on-call engagement On-call relies on alert playbooks maintained by service owner teams in collaboration with on-call engineers |
Non-critical alerts | Can be escalated to the on-call team if they pose a potential issue to our business Addressed by engineering teams during office hours |
To ensure visibility on all business-critical metrics, our SRE (Site Reliability Engineering) team regularly conducts observability workshops with our engineering teams. These workshops focus on identifying key metrics and critical alerts, defining alerting strategies, and establishing incident response measures. These workshops also provide an opportunity for aligning engineering teams with the best practices in alerting and observability, while ensuring that there is enough visibility on all business-critical operations.
The types of incidents our on-call engineers tackle
Besides our on-call model and processes, let’s discuss a bit more what type of incidents our on-call engineers might tackle. The primary incidents encountered by our on-call engineers often revolve around DDoS attacks, anomalies in resource utilization, or unexpected service behaviors impacting user orders. In most cases, these issues are handled by on-call engineers using the existing documentation and tooling available. Alerts are defined at service level granularity and the on-call engineer notifies the service owner teams about the issues even if it was resolved.
In case of issues that can’t be resolved without the help of subject matter experts, they’re escalated via the escalation path provided by the engineering team. If the issue spans multiple services, it’s escalated to company-wide forums to have all hands on deck.
As Wolt operates in 25 countries, it’s critical to ensure that our country operations teams get timely communication about any technical disruptions we might be dealing with. This is done by providing regular updates on incident resolution progress on company-wide forums. Our tech support team is responsible for providing these updates to country teams and informing them about any actions required from them.
How we make our on-call process even better 💙
Our current on-call model was introduced over seven years ago. While it’s been proven successful over these years, we acknowledge its limitations. As our platform grows in complexity, we also can’t guarantee to have all the right alerts in place for all critical issues in all of the 300+ services we maintain. We also can’t solely rely on a single engineer to run things, and documentation may not suffice.
To address these concerns, we're expanding on-call coverage across different engineering verticals to ensure multiple experts are available to handle issues promptly. Simultaneously, we're refining observability practices to detect issues earlier, reducing Mean Time to Detect (MTTD), and enhancing playbook quality to expedite Mean Time to Recover (MTTR). We are working closely with engineering teams to ensure that these best practices are adopted and there is a continuous feedback loop to ensure any improvements identified can be shared across the organization swiftly.
In the dynamic landscape of on-call engineering, continuous evolution and innovation are pivotal. At Wolt, our commitment to reliability drives us to embrace change and seek innovative solutions, ensuring that every incident becomes an opportunity for growth and refinement.
About the authors:
Ibbad Hafeez is Staff Engineer and SRE Competence Lead at Wolt, where his focus areas are site reliability and on-call. Ibbad is passionate about establishing a culture, where engineering reliability is prioritized.
Helena Anttila, Head of Tech Support has built Wolt’s internal technical support team which connects the realms of Engineering and Operations at Wolt. Her innovative approach to problem-solving and team management has enhanced operational efficiency in troubleshooting and technical escalations in our business. Helena holds a key role in managing site reliability efforts in Wolt’s on-call engineering organization.