Tech
Aug 3, 2023
How we manage incidents at Wolt

At Wolt, our primary focus is on delivering Wolt-grade experience to every user. To achieve speed and flawless execution in serving our customers, it’s essential that every aspect of our operations works harmoniously. From order processing with merchants, to payment handling and ensuring speedy completion of delivery tasks, each part of the process contributes to the overall seamless experience we aim to provide.
Despite our commitment to a world-class user experience, all incidents cannot be fully prevented. To mitigate any negative impact on our customers in such events, we have established a robust incident management process. Our incident management process relies on close collaboration between our operations and engineering teams. This process has been battle tested at Wolt since 2016, and changes have been made to accommodate the growth of our operations as we’ve scaled. In this blog post, we’ll cover:
How responsibilities are divided in our incident management process
How our incident management process functions
Lessons learned from scaling our incident management process
Future improvements and enhancements we have planned
So let's jump right in 🚀
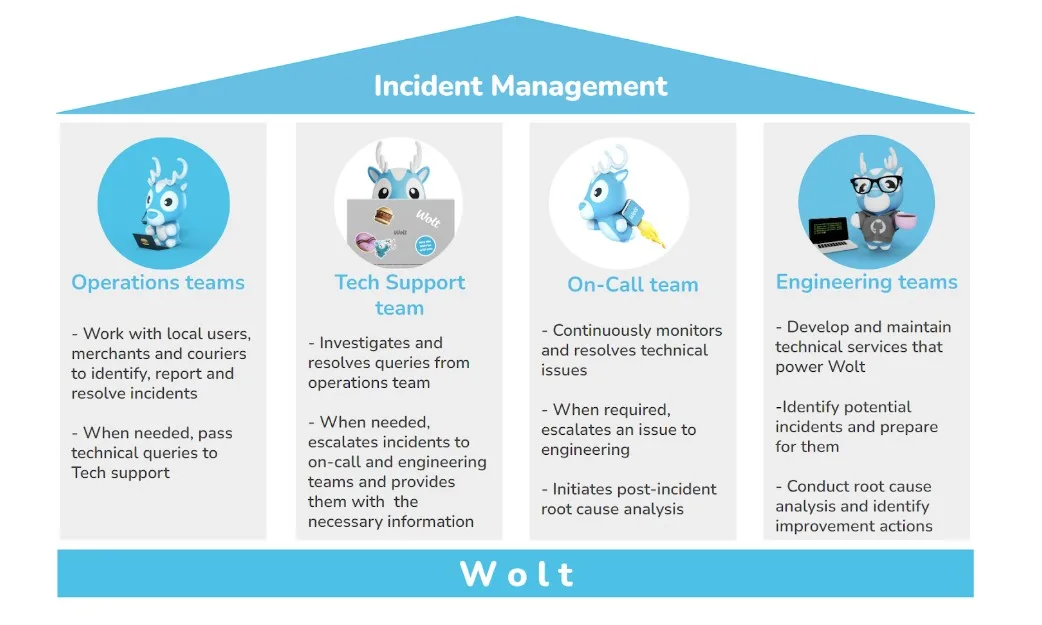
How teams collaborate to solve problems
Our incident process involves multiple parties from identifying a problem to solving it. Most often, an incident is found by an automated monitoring system or a dedicated country team. Our Tech Support team, along with the on-call engineer, assesses the scope and criticality of each incident and takes prompt action to resolve it and engage engineering teams and subject matter experts as needed. This collaborative approach minimizes the impact on our services and ensures a smooth experience.
In the below graph, you can see the key entities involved in our incident management process.
How we categorize incidents
Severity | Definition |
S0 | Most critical incident, indicating platform-wide unavailability. Resolving is a top priority and it is ‘all hands on deck’. Example: Complete Wolt platform outage. |
S1 | Incidents that prevent customers from making purchases. Share the same criticality as S0 but the scope might be restricted to one or few systems so not impacting the whole platform. Example: Being unable to process incoming orders. |
S2 | These incidents involve app feature issues, like a disruptive bug in the check-out view, affecting user experience without rendering the product non-functional. Resolving them promptly is a priority because they negatively impact the desired seamless customer experience. |
S3 | These incidents aren’t visible to customers and are handled during business hours. |
What happens when there’s an incident?
Escalating the incident
There are two main sources of detecting ongoing issues: automated monitoring and country operations teams. Country operations teams escalate issues reported by users, courier partners, or merchants to the Tech Support team who conducts preliminary investigations to determine the scope of reported problems and escalates to on-call if needed. If an issue is detected by our automated monitoring systems, it is directly escalated to engineering teams or on-call engineers depending on the severity of the issue.
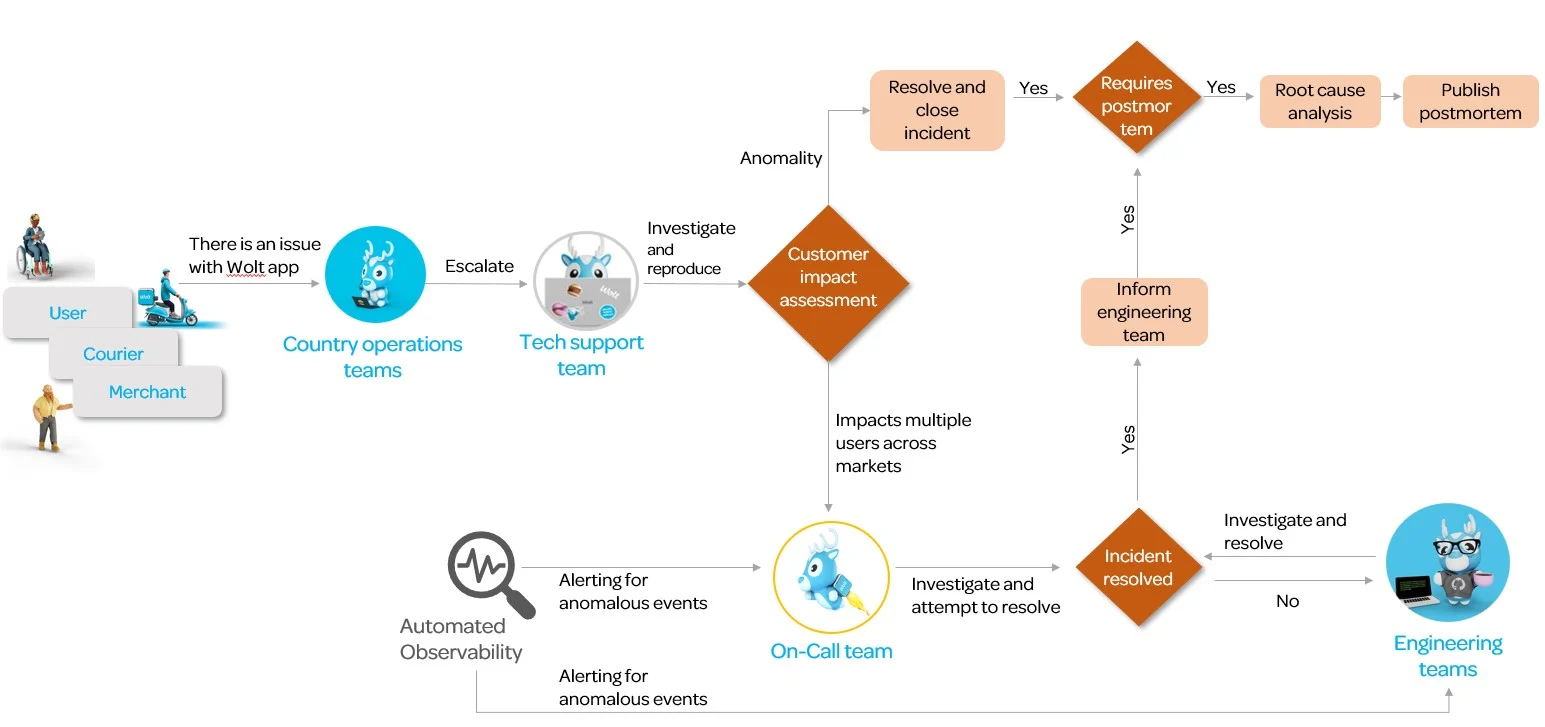
Fixing the problem 🚀
On-call engineer conducts early-stage technical investigations to identify the root cause of any reported issues. During this process, they use service monitoring, documentation, and other tools provided by engineering teams. Based on their investigation, the on-call engineer can either resolve the issue independently or escalate it to the relevant engineering team and subject matter experts (SMEs) for further assistance.
If the issue is caused by a third-party integration, it is escalated to the respective service providers using direct communication channels.
For incidents that have longer resolution times, on-call and Tech Support teams work together to provide regular updates to all teams within Wolt.
The aftermath - post mortems and RCAs
At Wolt, we strongly adhere to the engineering principle of "We don't fail twice for the same reason." Learning from our mistakes is paramount, and post mortems allow us to share the lessons learned across the organization.
After any incident, we typically have a high-level understanding of the root cause. We arrange Root Cause Analysis (RCA) meetings where the objective is to delve into the technical details of the incident, pinpoint the exact root cause and develop mitigation plans for the future. These meetings include on-call engineers, engineering teams and Subject Matter Experts (SMEs). RCA meetings and the key learnings are shared in the post mortem document.
Our postmortem process is transparent and open for anyone to participate. By leveraging the collective resources and experiences of our team members, we can swiftly resolve issues and extract valuable learnings that can be applied across various scenarios.
Post incident reach outs
For highly critical incidents resulting in prolonged downtime, our PR and comms team help us to communicate the issue with affected users and when needed, compensate for any degraded user experience.
What we’ve learned 😊
Communication, communication, communication
In an organization with over 8,000 team members across 25 countries, transparency and timely updates are crucial for business, operations, and engineering teams to stay informed about ongoing incidents. Our Tech Support and on-call team take ownership of company-wide communications, allowing engineers to focus on resolving the incidents.
Process to the rescue
To support the growth of our incident management capabilities, we’ve implemented a series of processes for incident escalation, engagement, resolution, and post-incident activities. These processes outline clear paths for escalation, establish effective communication channels, and ensure consistent postmortem analysis and communications.
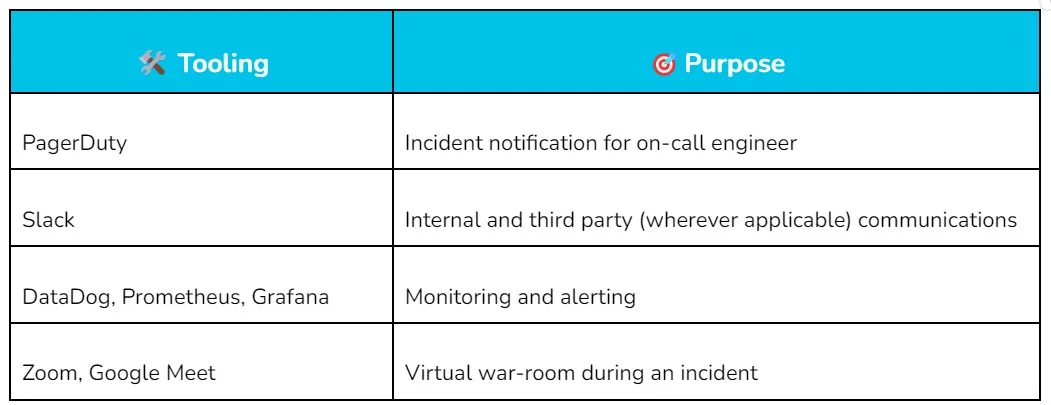
Great tooling takes you far
By leveraging great tools, we can achieve:
Early issue detection: Identify and address potential issues before they have a significant impact on users, allowing for proactive resolution.
Streamlined escalation and engagement: Relevant stakeholders can be quickly and efficiently engaged when incidents arise, ensuring prompt response and resolution.
Automated incident handling: Tools facilitate the automation of necessary steps in incident management, enabling swift and consistent action.
Progress tracking: Establish consistent processes for tracking the progress of incidents, ensuring transparency and enabling effective collaboration among teams.
Communication management: Seamless communication during and after incidents, enabling efficient coordination and information sharing.
By leveraging advanced tooling capabilities, we evolve our incident management process, enabling us to proactively detect, address, and resolve issues, while ensuring smooth communication and collaboration throughout the incident lifecycle.
Clarity is the key
Clear and up-to-date escalation paths are essential for efficient incident detection and resolution. At Wolt, we address this by creating comprehensive documentation, known as service runbooks and incident playbooks, which outline critical resources and their associated monitoring alerts.
Emergency preparedness
We strongly encourage teams to prioritize emergency preparedness in engineering work. This includes conducting load and performance testing, game days and other activities to ensure that our technical services can gracefully handle unforeseen issues such as high user demand during peak activity periods.
The future of incident management at Wolt
Over the years, our incident management process at Wolt has undergone significant evolution in parallel with the growth of our company. As we continue to adapt to our expanding organization, we recognize the need to enhance our incident management practices. In the near future, our primary objectives include:
Up-to-date documentation: We are prioritizing the creation of internal tools that enable faster access to up-to-date documentation for each service. This documentation will play a vital role in improving our ability to detect and resolve issues promptly.
Automation and tooling: We are actively developing tooling to automate the detection, escalation, and resolution of common issues. Our aim is to automate incident response playbooks as much as possible, reducing the need for human intervention and accelerating incident resolution with improved MTTx metrics.
Expanded Tech Support and on-call coverage: We are expanding the coverage of our Tech Support operations to operate 24/7. Meanwhile we are reorganizing our on-call structure to have additional expertise readily available in case of any incidents.
These initiatives reflect our commitment to continuous improvement in our operations, allowing us to provide exceptional service while minimizing disruptions to our customers.
✒️ This blog post was written by Ibbad Hafeez, Staff Engineer, and Helena Anttila, Head of Tech Support.
Interested in joining our team? Make sure to check out our open roles! 🚀